7th July - Sonic Sell v0.4, Voice Intelligence Layer improvements, padding parameters
SonicSell v0.4
SonicSell BetaIf you want an invite to the SonicSell beta email [email protected] or [email protected] and we'll get you invited
Automatic Language Detection:
Users no longer have to select the flag at the top right to select an output language.
We have implemented automatic language detection and it will automatically adjust your output to your input language.
This feature works for English, French, German, Spanish, Italian and Portuguese. 🇬🇧 🇫🇷 🇪🇸 🇩🇪 🇵🇹 🇮🇹

Advanced Mode:
Mood and Tone Indicator (BETA): Users can now suggest what the mood of the ad should be, and what the tone of the ad should be.
Multi-Versions: Users can produce up to 3 versions of the same ad in 1 go.
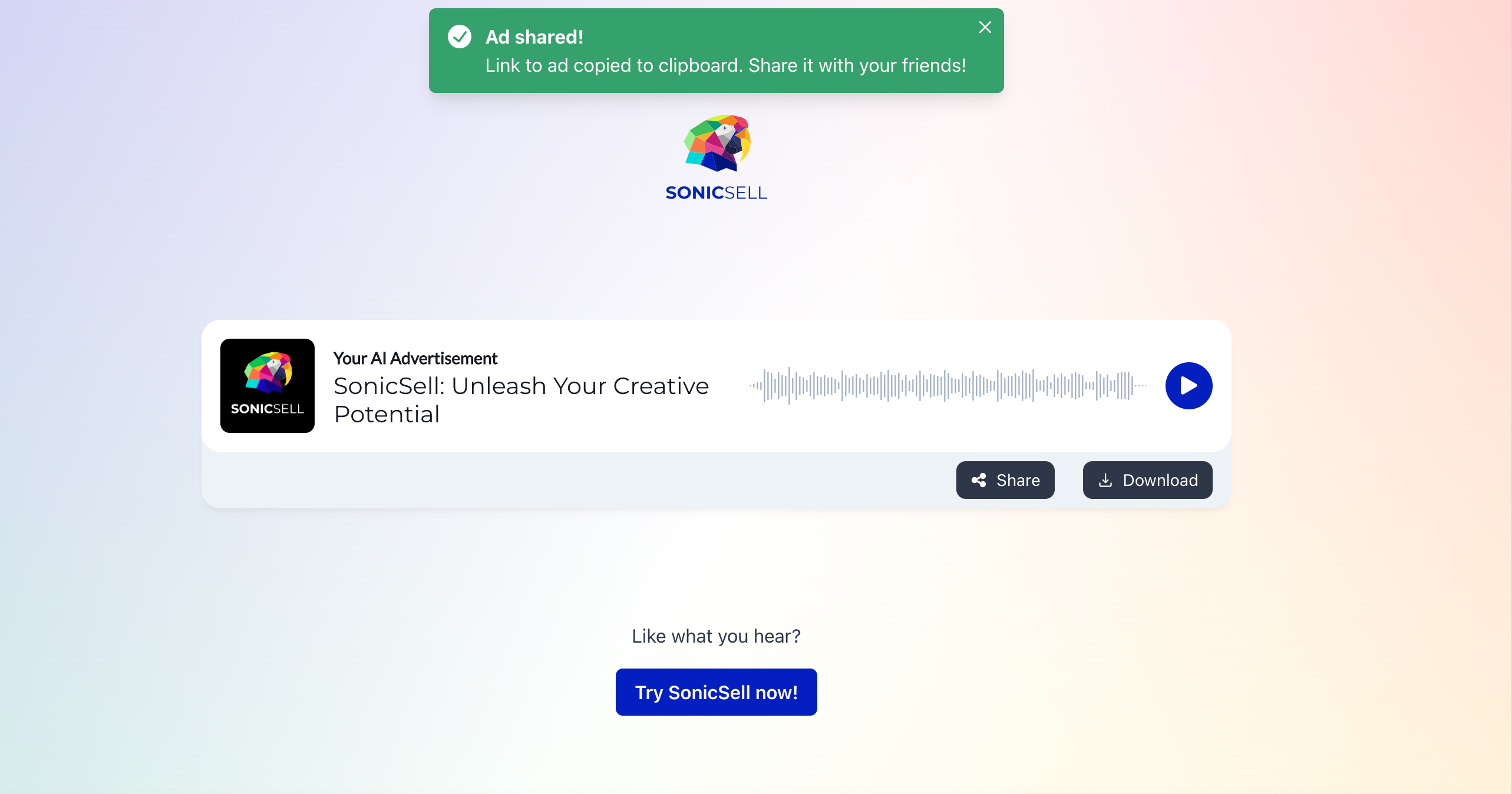
Virality Link:
Earlier, users would have to download the audio asset and manually share it with their friends and colleagues.
This was a very frictionful process, and wouldn’t work for us from a “word of mouth marketing” perspective.
Now, users can simply share a link that leads to an AudioStack page, where they can listen to the shared ad.
There’s a button there called “Try it now”, which is currently linked to a typeform where users can request access.
We are working on implementing the sonicsell trial flow on the website right now (will have it by next week),
Once that’s shipped, we will link this button directly to that trial flow.
Improved UI/UX:
Earlier, users could only truly generate and work with 1 ad. Not anymore,
Now, you can bulk generate 100s of ads in the same screen, and dynamically customise them as you go (without losing any progress of the other ads built in that session). Of course, once the session is refreshed, all that progress will be lost, since we are not saving the audioforms on a user level yet.
Additionally, users now also have the option to only “edit the ad” and not “generate” it at the same time. They can edit, see what they like and don’t like, and then generate as they please.
Also, now, if a request fails, we show them a beautiful failed card with a button to try to regenerate.
Migrated from WebSocket to HTTP
Earlier, if you were on the app for 30 mins, the websocket would time out which would result in failed generate requests.
Now, that’s no longer the case. With the migration to HTTP, we’ve seen a massive reduction in time-outs and failed requests, improving your user experience! 🚀
Voice Intelligence Layer improvements
We made some huge 🚀 improvements to the voice intelligence layer.
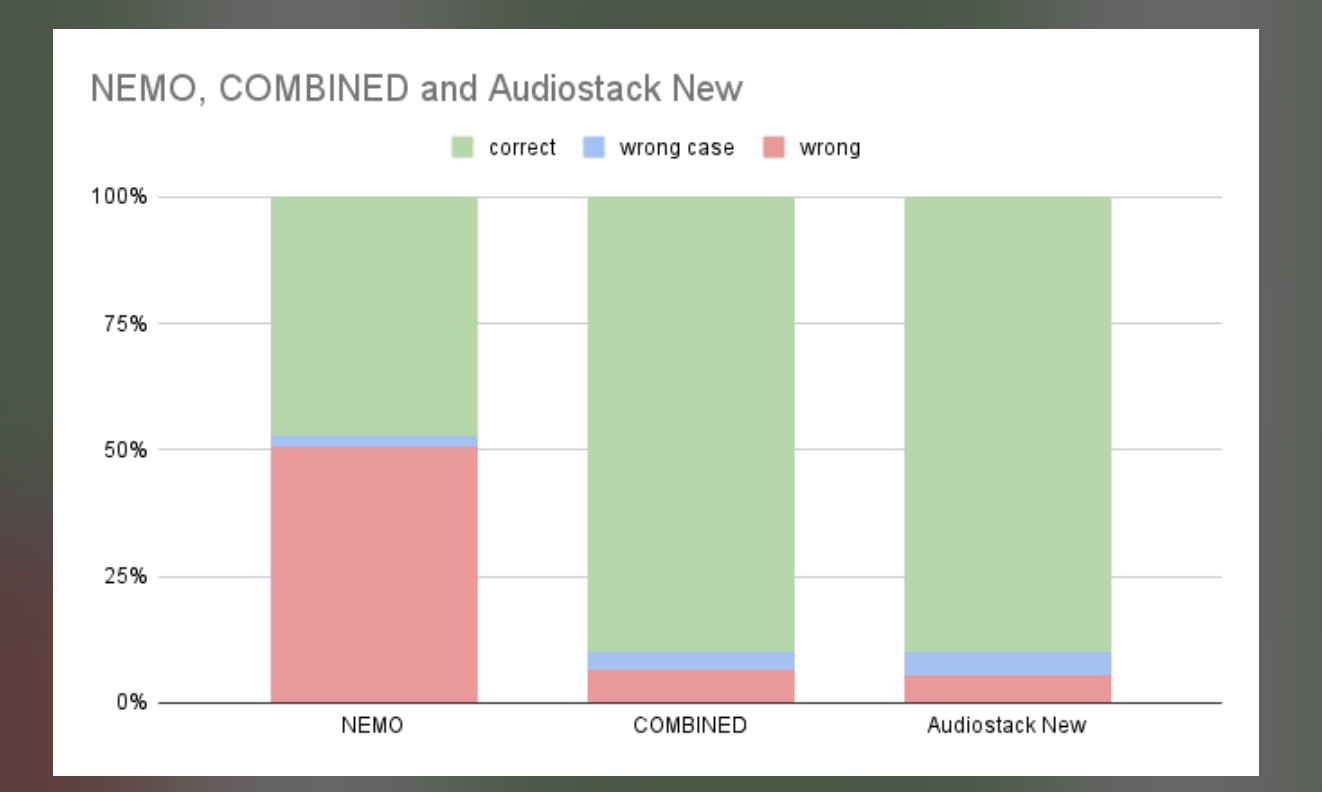
You can see a material improvement in the correctness on our internal data set compared to the NEMO project. We used this on a range of complex normalisation data challenges. We hope this enables you to have a much better user experience.
We also made a few more improvements
- SSML tags are removed before any processes are applied and replaced after. This was causing some edge cases and poor behaviour.
- Bug Breaktags no longer having normalisation incorrectly applied.
Feature Enhancement We also shipped improvements to the Eleven Labs voices. If you use the voiceIntelligence layer it'll apply our voice intelligence layer, and detect the language and pronounce the numbers correctly. For our 🇩🇪 customers this is super valuable.
Here's an example. Use the Wren voice from Eleven Labs for example for this.
"scriptText": "<as:section name='intro' soundsegment='intro'> heute ist der 12.12.2012</as:section>"Padding Parameters
We added two new padding parameters
- timelineProperties: {padding : seconds} adds padding between each section
- sectionProperties: {sectionName : {padding : seconds}} adds padding after a named section
Loudness presets
We added a range of loudness presets - here's a simple example.
# test list encoder and loudness presets
a = audiostack.Delivery.Encoder.list_presets()
print(a)
# test wav encoding with spotify loudness
encoded = audiostack.Delivery.Encoder.encode_mix(productionId='PRODUCTION_ID',
preset='wav',
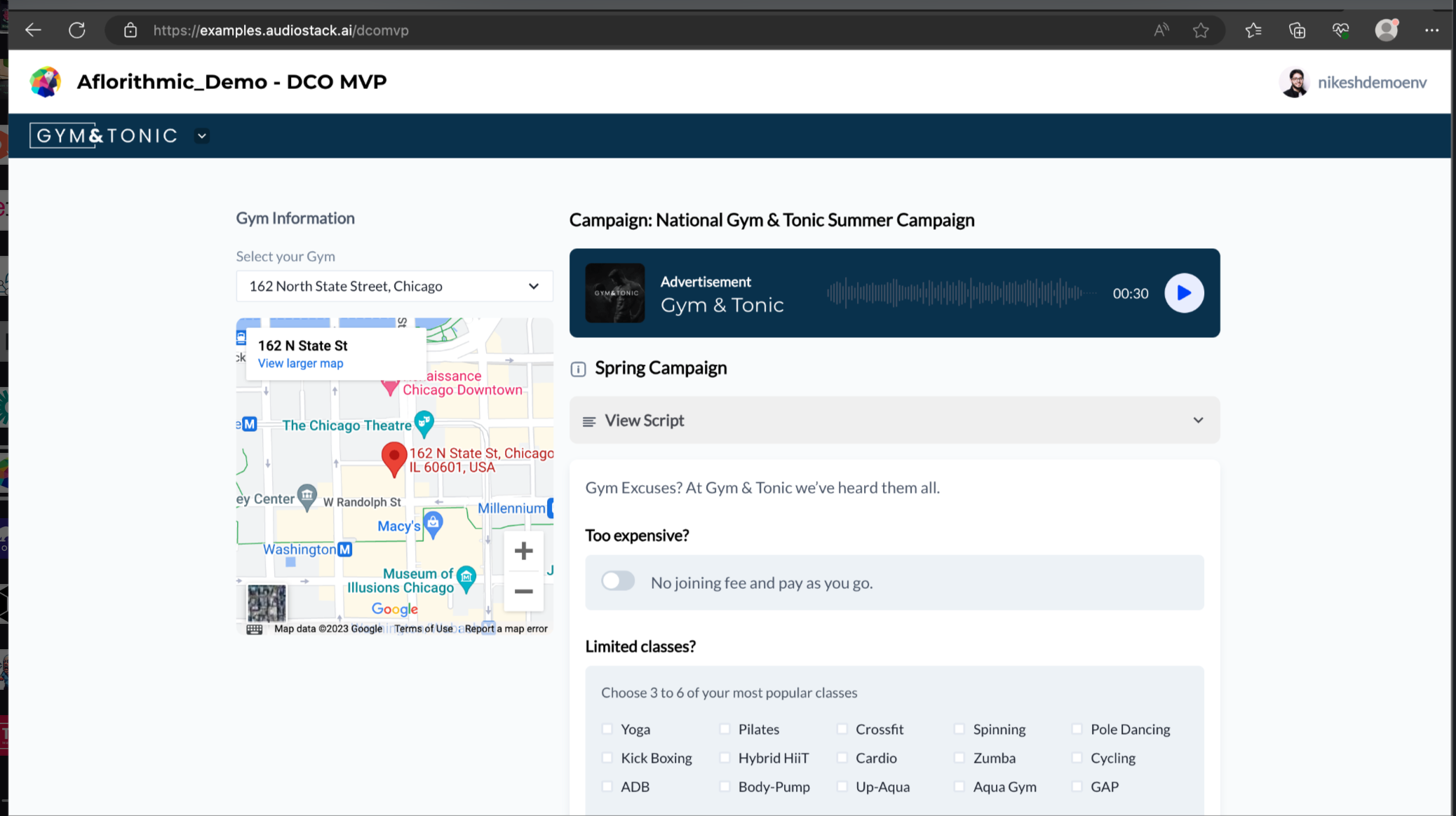
loudnessPreset="spotify") DCO MVP
We shipped a few weeks ago the following digital creative optimisation - this features a fictional audio campaign of a fictional gym and tonic brand!
You can see in this campaign that it personalises the audio based on some specific parameters, so you can better connect with your customers.