Many of the voice providers in our library add padding to the end of speech files by default, so that sentences don't end too suddenly. There are some situations where users have reported needing to remove this padding so that they can specify a more precise, consistent amount of padding across different voices and providers. This is now possible using /speech/tts/remove_silence.
M4A Encoding
🔊 AudioStack now supports M4A encoding. Simply specify "m4a" as the preset to use this feature.
Javascript SDK Quickstart
We added a quick start guide to get Javascript developers up and running using our SDK. You can find it here.
If you have any feedback about our documentation or would like to request docs on specific workflows, please get in touch at [email protected].
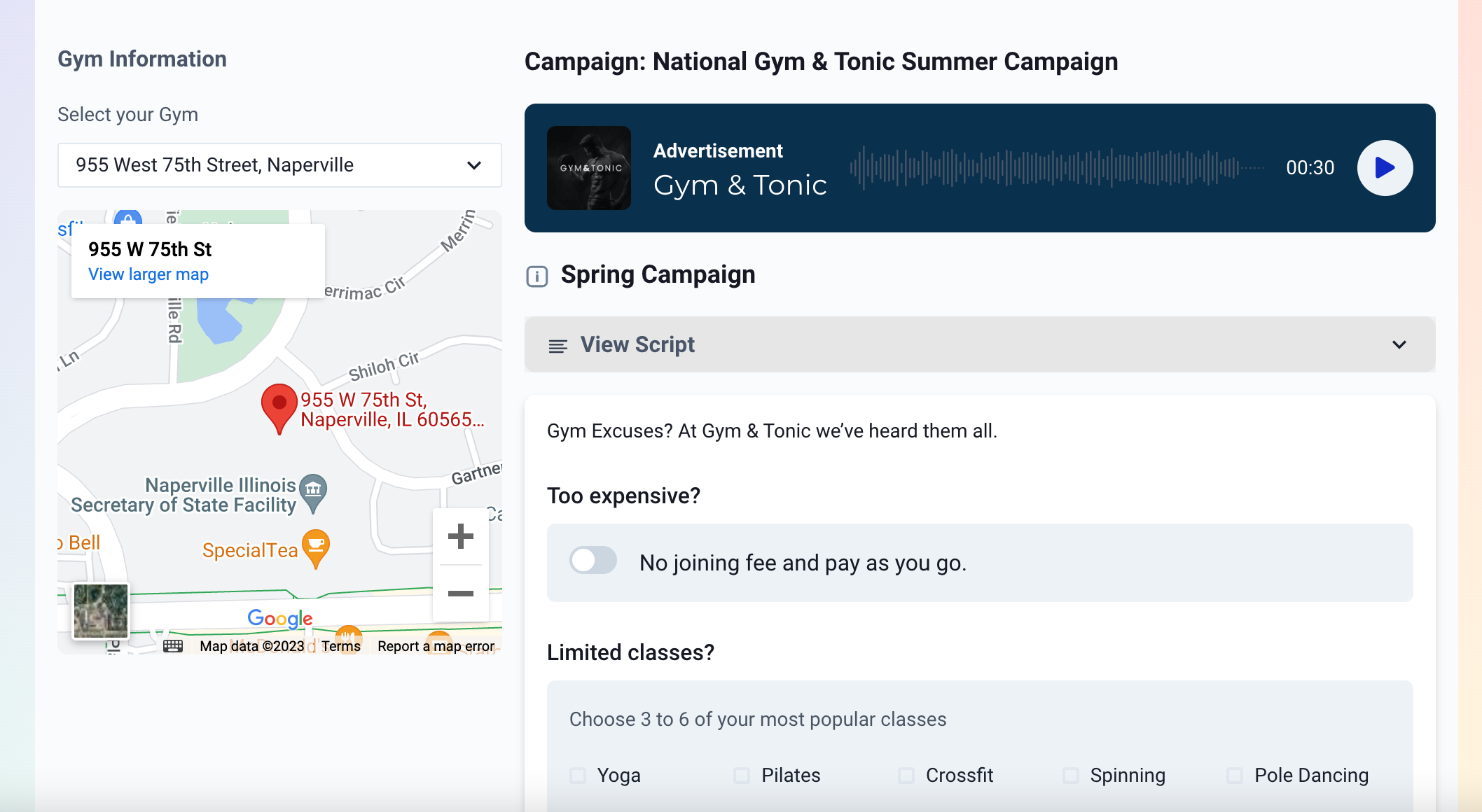
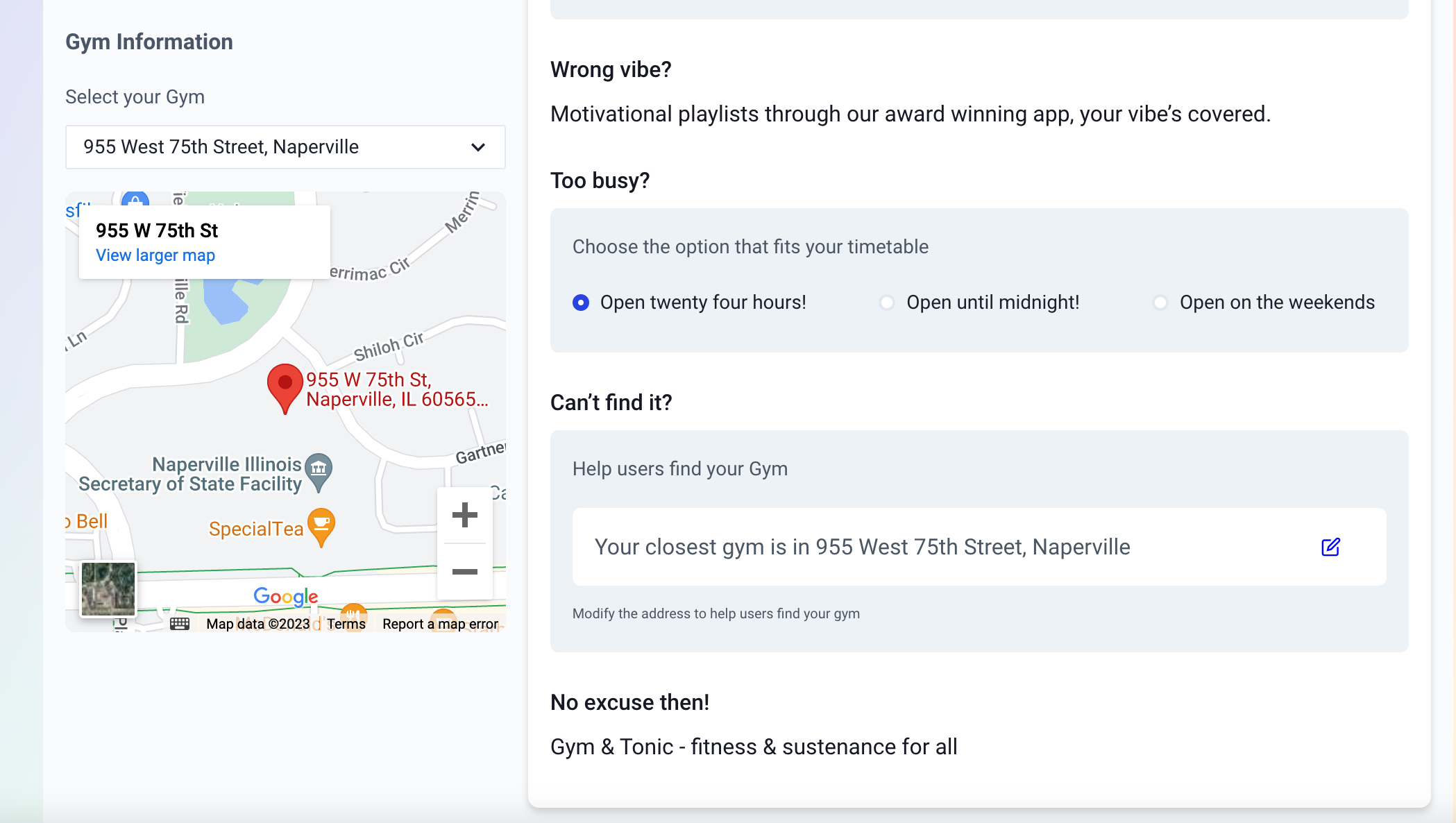
This enables you to run localised national radio or podcast campaigns.
A screenshot of some of the options 💯
Bug Fix - Voice Intelligence layer
Our customers reported a 🐛 where the dictionary was incorrectly updated, this turned out to be an edge case involving some ~being passed into one of our systems. Well done to the engineering team for hunting this one down, this was a hard one! 🎩
We are constantly working on bug fixes and improvements to our systems.
Improved Incident Response Systems ⏰
We invested heavily this week in improving our internal alerting systems - this is to further enhance our reliability. The improvements were rolled out this week 💯
Voice Intelligence Layer Quality Enhancements
We added 2500 tests to our continuous integration system, enhancing the quality of our product and the customer experience.
A Couple More Layered Sound Templates... [beta]
We've made sound layering available for the following templates:ambient_electronica, eighties_chill
These now have intense, soft and default intensity options. For more information about the layered sound template beta, see our previous ChangeLog post.
New feature allows you to specify how intense you would like a specific sound template to sound, changing the "timbre" of the sound design.
For example, a more intense sound template might include heavier percussion and more complex melodies. A soft version of the template might sound more sparse, with just melodic instruments and chords, for example.
To use this feature, you need to specify which of the "soundLayers" to use in the mix: choose from soft, intense, or default.
This feature can currently be used with two supported sound templates: chromatic_jazz and friendly_electronica.
import audiostack
import os
audiostack.api_key = "APIKEY"
audiostack.api_base = "https://v2.api.audio"
print(audiostack.Production.Mix.list_presets())
scriptText2 = """
<as:section name="intro" soundSegment="intro">
Insert your script for the intro section here
</as:section>
<as:section name="main" soundSegment="main">
And this is the main section!
</as:section>
<as:section name="outro" soundSegment="outro">
Here is your outro.
</as:section>
"""
script = audiostack.Content.Script.create(scriptText=scriptText2)
print("response from creating script", script.response)
scriptId = script.scriptId
# create one tts resource
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="bryer")
print(tts.speechId)
sound_template = "chromatic_jazz"
sound_layer = "intense"
mix = audiostack.Production.Mix.create(speechItem=tts, soundTemplate=sound_template, masteringPreset="musicenhanced", soundLayer=sound_layer)# sectionProperties={"main" : {"endAt" : 120}})
print(mix)
encoded = audiostack.Delivery.Encoder.encode_mix(productionItem=mix, preset="wav")
encoded.download(fileName=f"{sound_template}_{sound_layer}")
👍
We love to receive feedback about beta features
If you have any thoughts on this feature, please get in touch at [email protected].
We'll be launching a more extended version of this feature which supports lots more sound templates soon.
Mastering Improvement
We added MP3 support for media files in mastering - this means you can upload MP3 media files and include them in your final asset
🚧
Don't forget to update the SDK to access new features
In Python, you can do this by running the command pip3 install -U audiostack
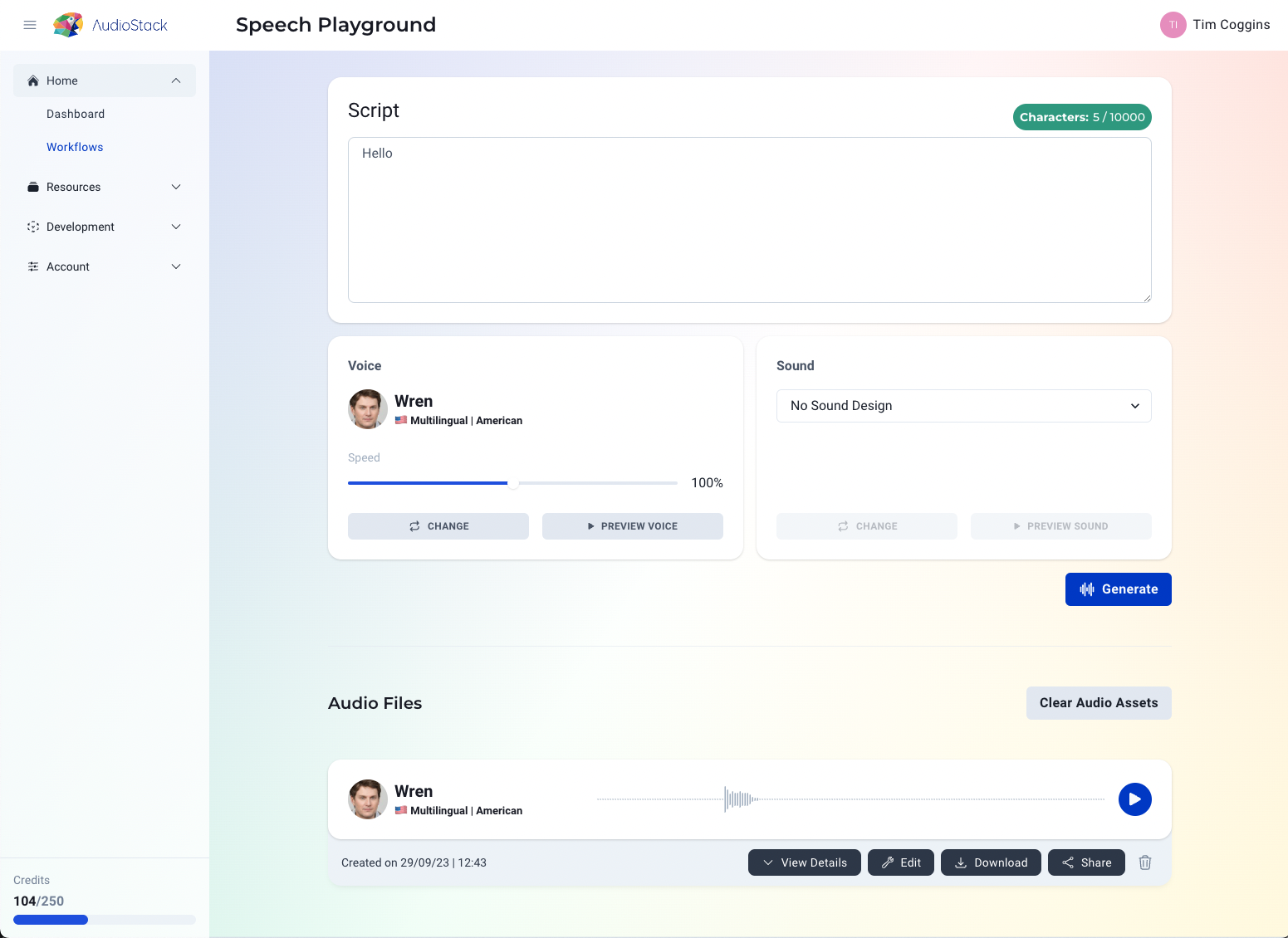
New features in Platform. Save audio assets locally, so that your session is saved, improving the customer experience.
New mastering preset 🎉
We added a "voice only" preset (mastering engine feature) 💯
By using this preset, mastering will only applied to the generated voice and not the sound design beneath it. This is perfect for cases where you've already applied mastering to the sound template (or received a finished advert that you want to add an audio tag to).
We've added a new endpoint which draws on 4 million data points to predict the duration of speech from a given script and list of voice names 🤓
This will allow users to determine whether a voice is suitable, or whether their script is the correct length for their project, without needing to generate the audio itself, saving time and credits! ⏰
Find out more and check out a code example in our guide, in the API reference or in the video below 👇
Sound template terms of use have been added for free and paying customers - we can now refer to the terms of use if people have questions about how they are allowed to use our templates.
This doesn't mean that our old API was insecure, we're committed to updating and reducing any risks of compromise to our customers. We regularly review security updates, and we regularly patch any found errors.
We did a range of fixes to cover some security issues. These include
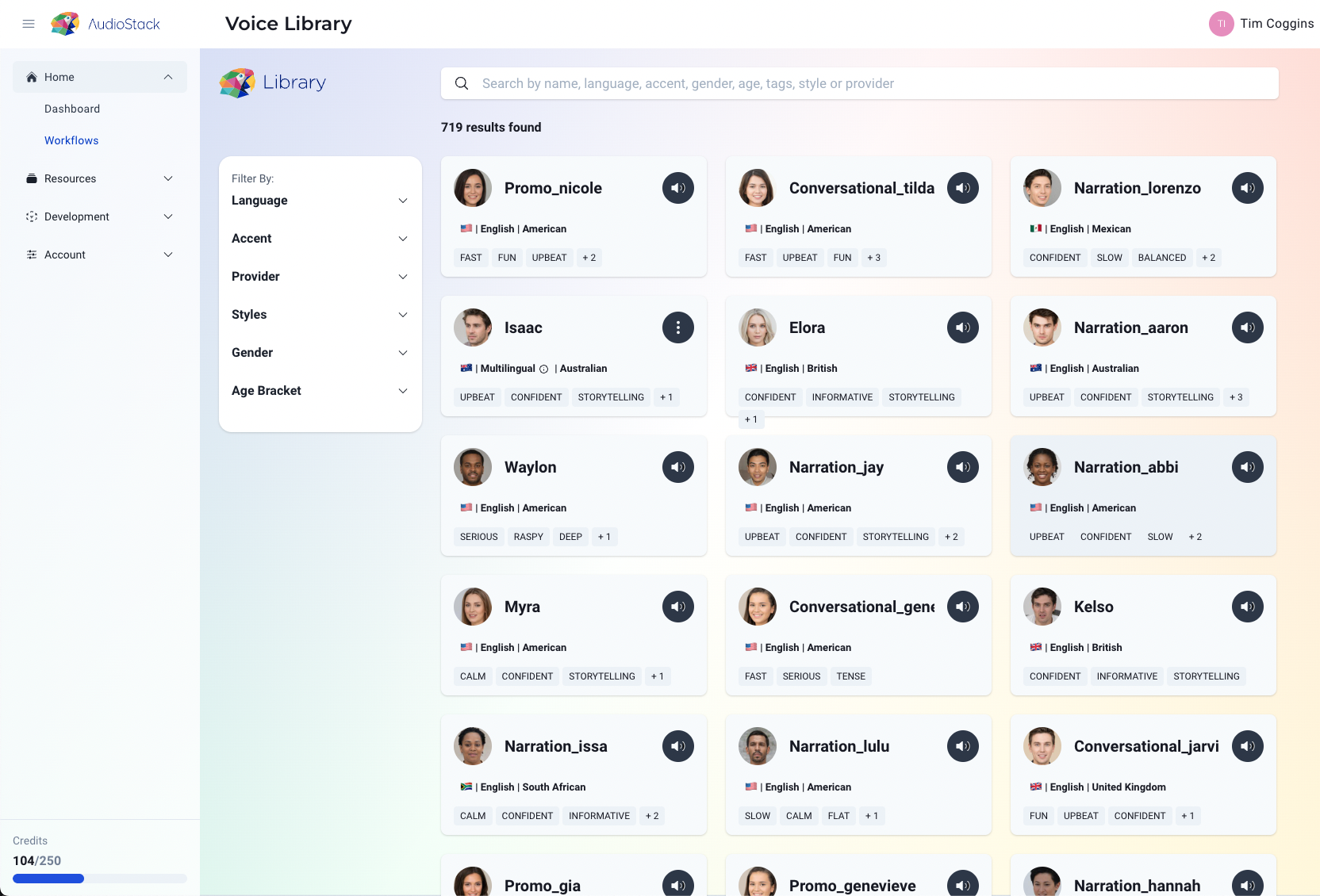
Is completely reusable and can be accessed at: http://library.audiostack.ai in the platform as a standalone workflow with the ability to preview, and in the voice select modal in the voice playground and sonic sell
SSML Prosody
We added the following functionality to have better prosody across providers. , ,
import audiostack
audiostack.api_key = "APIKEY"
text = """ The following part should be <as:prosody pitch="x-high" rate="x-fast" volume="x-loud">higher, faster and louder</as:prosody>,
"""
script = audiostack.Content.Script.create(scriptText=text)
print(script.message, script.scriptId)
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="henry", voiceIntelligence=True)
print(tts)
item = audiostack.Speech.TTS.get(tts.speechId)
item.download()
You can now access v2 of ElevenLabs' multilingual voices via AudioStack, a major improvement in terms of improving content accessibility through language localisation. 🎉