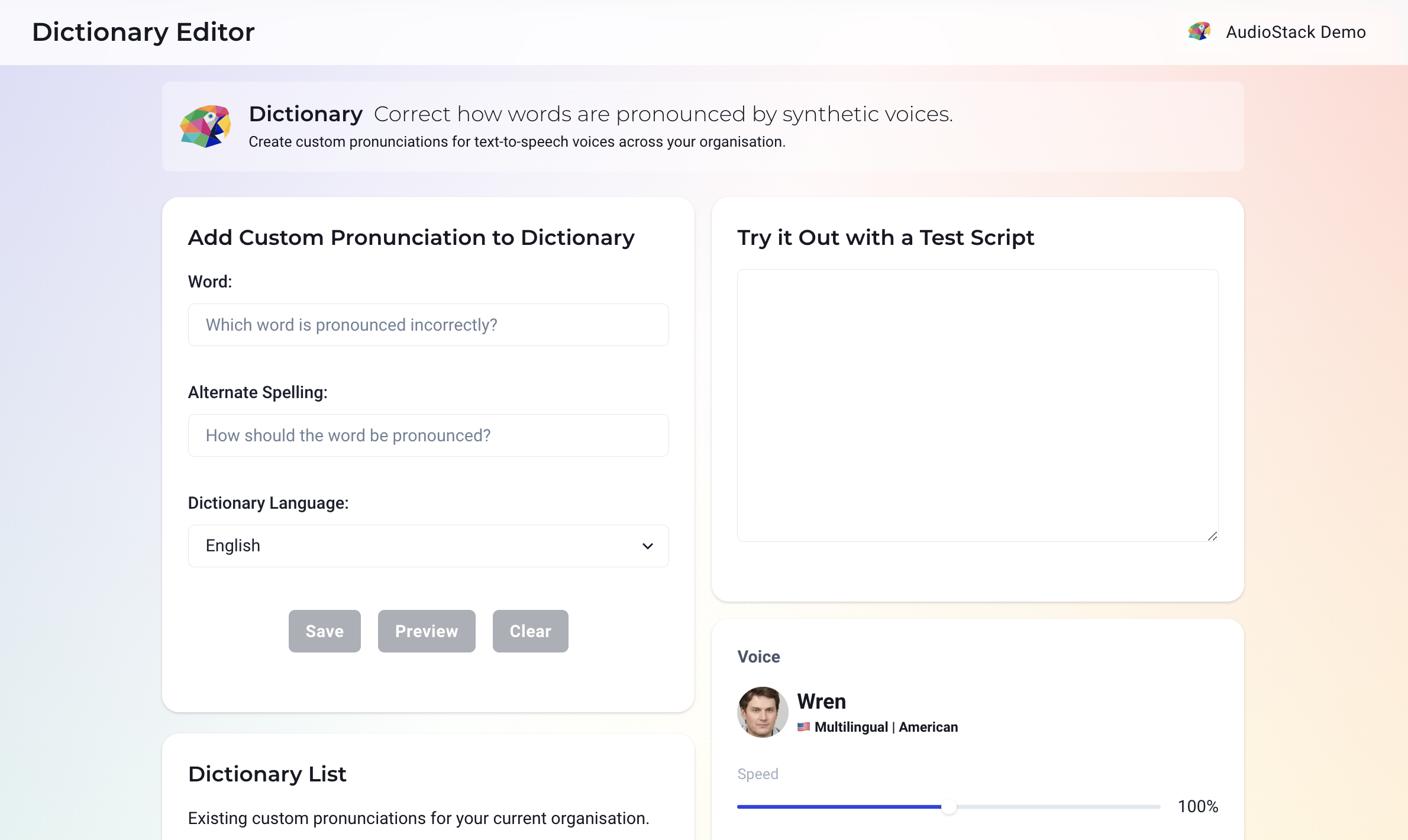
In the last release of the AudioStack Platform, we added lots of new functionality.
SonicSell:
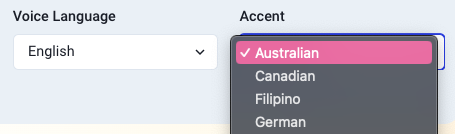
- You can now specify the accent you'd like a voice to have. Simply select the language of your script and choose an appropriate accent from the dropdown.
- We added the audioform ID (used to identify your asset) to all ad cards, to make it easier to work out if you're editing the right version.
Recording Booth:
- Made it easier to record without a script, and added a "Save As" button to make it easier to find your recorded files.
Platform:
- Report an Issue with the click of a button. Our team will be notified so can more easily troubleshoot issues.
- Clarified the acceptable file names in our file upload modal, to improve the UX of file upload.
Speech Playground:
- Added option to customise the asset name so that when you share an asset, the recipient can tell what it is.
Developers:
- We renamed the "AudioStack for Developers" page to "API Key", based on feedback, to make it easier to find your API key.