Audioform Format
What can audioform do?
Typically one can create a piece of audio like this with audioform:
Import and create assets
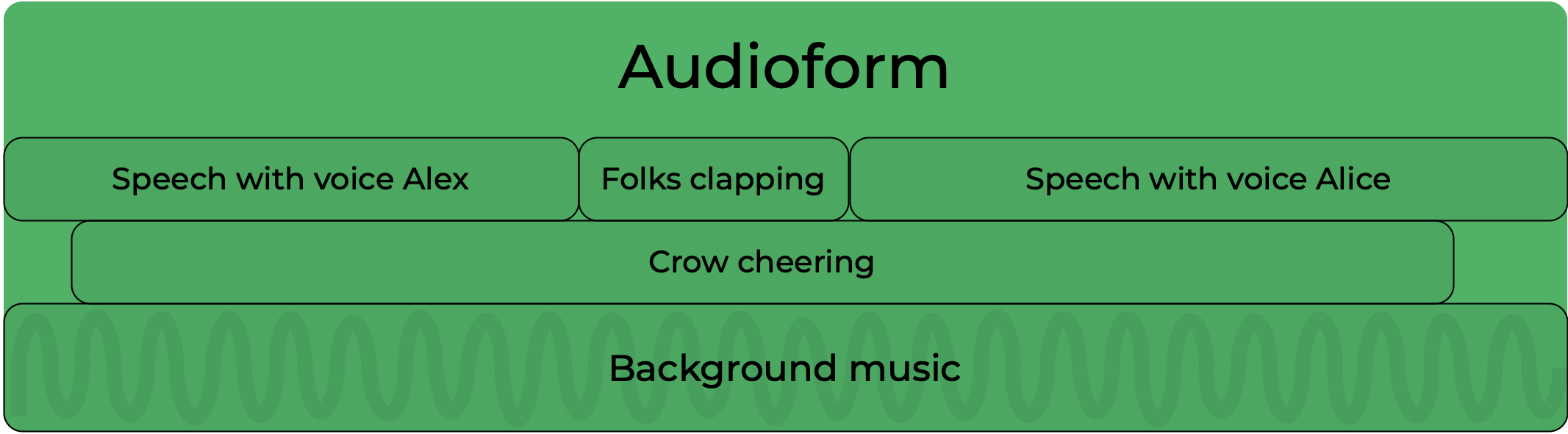
Audioform arrange together and mix different kind of elements (called assets). Those are:
- Text-to-speech (a combination of text and a voice from the Voice library)
- Speech-to-speech (a combination of a text recording and a voice from the Voice library)
- Sound effects (a sound from the Sound effect library)
- Sound template, or sound bed (a sound from the Sound template library)
- An audio file from the File library
Arrange
The assets are arranged via an arrangement that lay them out over time and determines the relative position and overlap of the assets.
The arrangement is first divided in consecutive Sections (minimum one):

Each section contains one or more layers playing together. It has an optional sound template (or sound bed) that will play in the background of the section, and will play for the duration of the section:
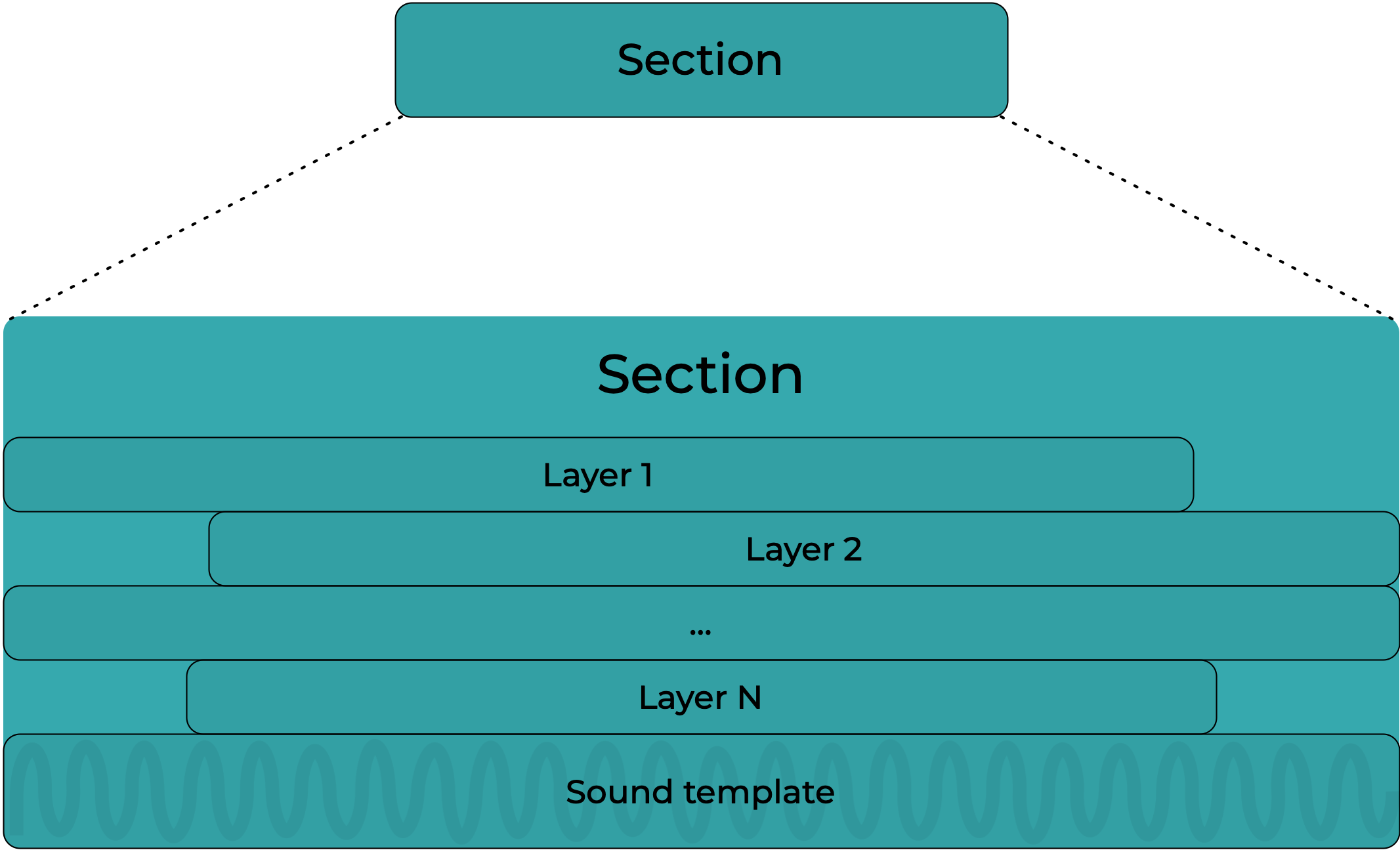
The Smart Fit feature will fit the sound template perfectly to the section, doing a smart edit of the sound template combining the start and the end of the music in one piece.
Each layer contains contiguous clips. The clips contains one asset.

Timing and duration
The audioform arrangement is designed to be flexible: it can adapt to its content (the assets) but can also have timing constraints such as:
- forcing the duration of a section or a clip
- add a pause (no sound) between two consecutive sections or clips
- align layers with each others
Produce
The arrangement is mixed by our cloud mixing engine.
The engine has knowledge of the asset types and is therefore able to process them differently, irrespective of the layer they are in, so that the result always sounds great.
If you have knowledge of Audio production software (DAWs), do not equate the concept of tracks in a DAW to that of Layers in Audioform as different assets in the same layer could end up in different tracks in our mixing engine. The Arrangement is about timing essentially.
The mixing presets supported by audioform are the following:
-
musicenhanced: focuses on the music in the soundFor music-richer content. Minimal attenuation on music for fuller, louder music bed. Voice sits “in the mix” rather than on top
- Smooth ducking keyed by voice
- Voice EQ’d and controlled but not dominant
-
voiceenhanced: focus on the voice at the expense of the music
For speech-first content (narration heavy formats). Voice is always foregrounded. Music becomes contextual rather than competitive.- Smoother side-chain keyed by voice (seemless) and significantly reduced music levels.
- multi-stage master compression and safe threshold limiting
-
balanced: balanced between music and voiceGeneral-purpose, equal priority between voice and music. Voice remains intelligible without fully suppressing music. Suitable when music is present but not dominant
- Side-chain compression on music buses keyed by voice and moderate music attenuation.
- multi-stage master compression and safe threshold limiting
Delivery
The mixed result is then further process to fit a specific loudness target (which some broadcast system require) and encoded to a specific format.
Encoding Presets
These determine factors like the sample rate and format of your delivered file. For most casual uses, such as sharing a demo with a colleague by email, MP3 is considered standard. When you need higher quality audio, such as for professional editing, an uncompressed format (such as WAV) or lossless format (such as FLAC) is usually more appropriate.
| Preset | Description |
|---|---|
| mp3 | mp3 format 320k (320 CBR) Low audio quality, low file size. So really useful for low quality streaming (e.g. over 3G or when quality doesn’t matter). Supported universally across platforms and operating systems, so good for sending files on mobile devices, putting on websites etc |
| wav | wav format at 48 kHz sample rate and 16 bits per sample. High quality, large file size, uncompressed. Great for high quality storage and widely supported. |
| ogg | ogg format at 320k Higher quality audio than MP3 (320kbps) but similar file size, so can be useful for developers trying to distribute sounds! However, not universally compatible, so better suited to e.g. audio streaming applications. |
| flac | flac format at 48 kHz sample rate and 16 bits per sample. High quality, large file size. Lossless (but compressed, so a smaller file size than WAV). So great for storing professional quality recordings, but less useful for consumer streaming. Open source so generally well supported. |
| mp3_very_low | mp3 lowest quality (~64 kbps VBR) |
| mp3_low | mp3 low quality (~115 kbps VBR) |
| mp3_medium | mp3 medium quality (~165 kbps VBR) |
| mp3_high | mp3 high quality (~190 kbps VBR) |
| mp3_very_high | mp3 very high quality (~245 kbps VBR) |
| mp3_alexa | mp3 format mono at 48kHz sample rate |
| mp3_alexa_48br | mp3 format mono at 48 bit rate and 24kHz sample rate |
| m4a | m4a format at 320k |
Loudness Presets
It's also possible to specify the loudness required. This is particularly useful when you're planning to deliver the same asset across different media - for example, to deliver an ad for both Spotify and Radio broadcast.
| Preset | Description |
|---|---|
| streaming | -16 LUFS Loudness Integrated and -2 dB True Peak |
| radio | -11 LUFS Loudness Integrated and -1 dB True Peak |
| podcast | -16 LUFS Loudness Integrated and -3 dB True Peak |
| applePodcast | -16 LUFS Loudness Integrated and -1 dB True Peak |
| youtube | -14 LUFS Loudness Integrated and -1 dB True Peak |
| lowVol | -20 LUFS Loudness Integrated and -5 dB True Peak |
| podcastDynamic | -18 LUFS Loudness Integrated and -1 dB True Peak |
| radioAdvertising | -7 LUFS Loudness Integrated and -0.1 dB True Peak |
Some delivery settings lead to higher quality sounding audio than othersFor radio broadcasting, audio assets need to be particularly loud. For other use cases, we'd recommend avoiding the
radiopreset and choosing the description that's most appropriate to you.
radioAdvertisingwill lead to distortion/artefacts if mis-used:
- These targets is intentionally extreme, it will push hard toward the loudness target and use compression and limiting aggressively.
- If the source material is unsuitable:
- Audible pumping or distortion may occur
- This is expected and acceptable for commercial radio delivery
Metadata in the produced audio
The produced audio file contains meta data identifying that the file has been created by Audiostack.
The data will be marked as AUDIOSTACK_META and look like this
{
"version": 1,
"id": <audioformID>,
"engine": "audioform",
"message": "This audiofile contains elements produced by AI.",
"author": "www.audiostack.ai",
}Depending of the file type this is how to find the metadata:
- In
mp3, the metadata in aTXXX:AUDIOSTACK_METAframe. - In
wav- the metadata is in a'id3 'riff chunck - {AUDIOSTACK_META={<our JSON>}} - In
oggandflacthe metadata is in a Vorbis comment - {AUDIOSTACK_META={<our JSON>}} - In
m4Athe metadata is in a freeform atom (----)- mean:
ai.audiostack - name:
AUDIOSTACK_META
- mean:
How to check for the metadata
ffprobe -hide_banner -loglevel error -show_entries format_tags:stream_tags -of json "<path to the audio file on disk>" | grep -i audiostack Updated 28 days ago