We've also been heavily involved in making our systems more stable and enhancing our security and control systems.
Validation
We have added a validation route in mastering: https://docs.audiostack.ai/reference/validatemix
This allows you to validate your mastering request before sending it (and consuming credits) great for use cases involving user defined start and end values.
Here's a demo example in some code. Run this and listen to how awesome the audio sounds 🎧
We've added enhanced plugins - you'll see some presets below they are aimed at making your audio sound superb.
We're working hard on adding more sound templates and will be adding more to this in the future.
import audiostack
import os
from uuid import uuid4
audiostack.api_key = "APIKEY" # Add your API key here
script = """
<as:section name="main" soundsegment="main">
Are you ready to explore the vibrant city of Barcelona? Do you want to experience the culture, the nightlife, and the beauty of this incredible city?
Then we've got just the thing for you!
Join our travel agency for an unforgettable trip to Barcelona. Experience the bustling city streets, the stunning canals, and the charming architecture that Amsterdam is known for. Get lost in the vibrant nightlife,
explore the world-renowned museums, or simply soak in the local culture.
</as:section>
"""
names = ["Wren", "jollie", "aspen", "monica"]
presets = ["musicenhanced", "balanced", "voiceenhanced"]
templates = ["your_take_30","listen_up_30", "future_focus_30"]
script = audiostack.Content.Script.create(scriptText=script, scriptName="test", projectName="ams_tests_2")
for name in names:
# Creates text to speech
speech = audiostack.Speech.TTS.create(
scriptItem=script,
voice=name,
speed=100
)
for template in templates:
for preset in presets:
mix = audiostack.Production.Mix.create(
speechItem=speech,
soundTemplate=template,
masteringPreset=preset,
)
print(mix)
uuid = uuid4()
mix.download(fileName=f"V4_{name}_{template}_{preset}")
print(mix)
We are constantly investing in better products and services for our customers so we'll occasionally be changing some things in our pricing systems
We recently updated a few things in our pricing systems, this is to improve the customer experience, you shouldn't notice much change except a few cheaper endpoints.
We changed the £50 extra credits limit to £300 - so you'll be charged less frequently. This is due to customer feedback 💯
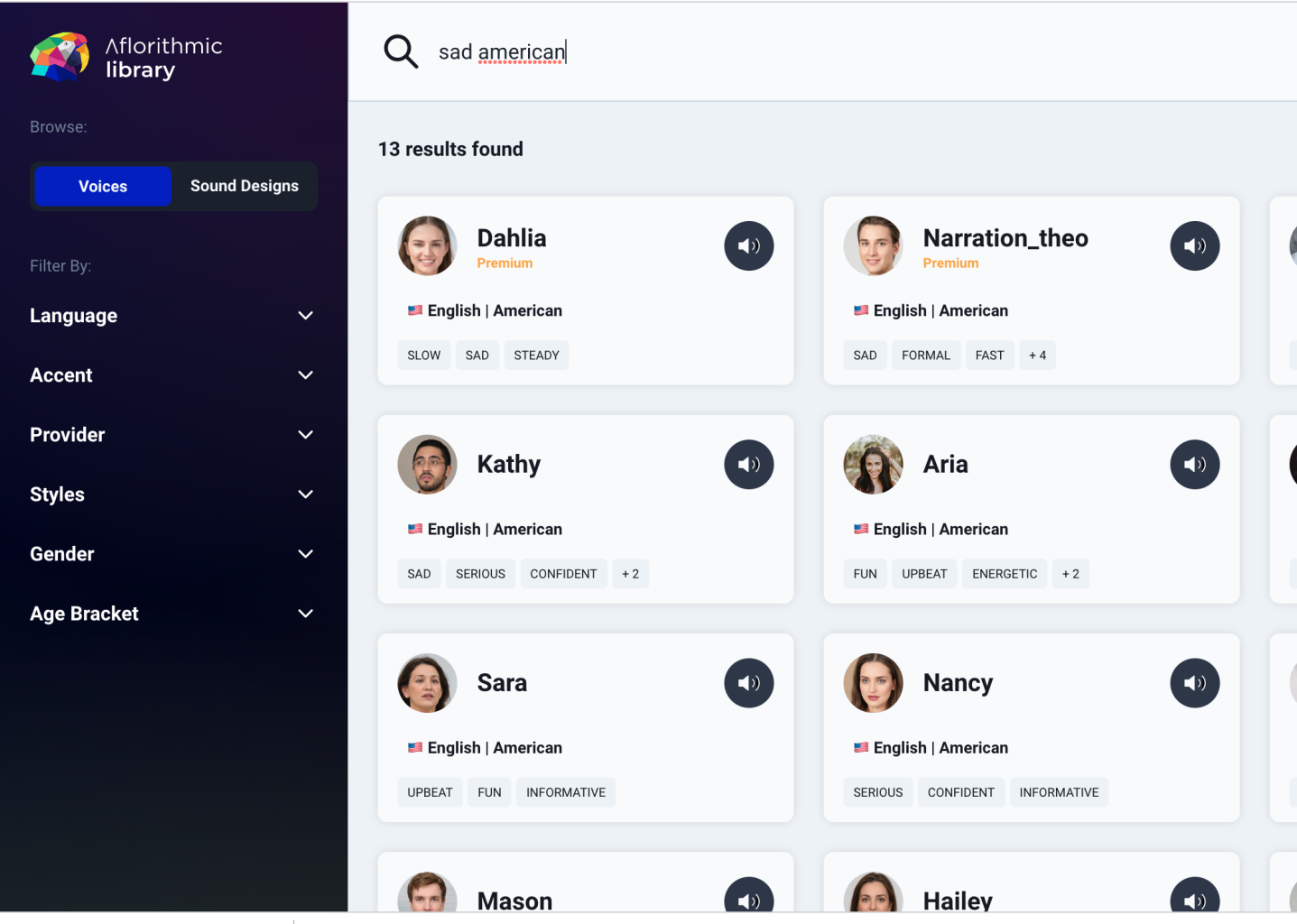
We recently completed a full rewrite of our voices library. This is to allow us to handle security better - we take this seriously, and also to allow users to find voices faster.
We redesigned our library management system using Contentful, adding validation.
We added an integration between our voice systems and our search engine - which will enhance voice discoverability in our frontends.
We also added enhanced voice permissions, authentication and integrated with our user and organisation permission system.
Lots of this is under the hood, but it's an example of the sort of customer experience and operational excellence processes we're investing in. Well done to all in the team! Migrations are hard! 🗻
Voice Intelligence layer - Abbreviations and Ordinal numbers
We've been hard at work on our voice intelligence layer 👌
Ordinal Numbers
📘
Definition of Ordinal numbers
A number defining the position of something in a series, such as ‘first’, ‘second’, or ‘third’. Ordinal numbers are used as adjectives, nouns, and pronouns.
The Voice Intelligence Layer is now able to normalise ordinal numbers in German 🇩🇪. It covers all ordinal numbers in the format X. that are used as adjectives. Here’s an example:
import audiostack
import os
audiostack.api_key = os.environ["AUDIO_STACK_DEV_KEY"]
text = "Ich war wie im 7. Himmel"
script = audiostack.Content.Script.create(scriptText=text)
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="lena", useDictionary= True, useTextNormalizer= True)
print(tts.data['sections'][0]['preview'])
Out:
"Ich war wie im siebten Himmel."
Abbreviations
The Voice Intelligence Layer is now able to expand German abbreviations to their full form. It covers the 130 most frequent abbreviations in German. Here’s an example:
Here's some examples
import audiostack
import os
audiostack.api_key = os.environ["AUDIO_STACK_DEV_KEY"]
text = "Ich kenne eine Abk. zum Bhf. von Ulm."
script = audiostack.Content.Script.create(scriptText=text)
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="lena", useDictionary= True, useTextNormalizer= True)
print(tts.data['sections'][0]['preview'])
Out:
"Ich kenne eine Abkürzung zum Bahnhof von Ulm."
After launching AudioStack API & Python SDK, we've continuously worked on more features to free up your engineering resources. Now you can easily integrate our API using our new JS SDK, a lightweight library that makes it easy to create professional audio assets within seconds.
We've design it to simplify the coding process - create a script, choose one of our 600+ voices, add a sound design and voila - you can encode your audio file as a high quality mp3 and download it. This allows you to focus on creating great audio experiences without having to worry about the underlying code. 🚀 💯
npm install @aflr/audiostack
# or
yarn install @aflr/audiostack
How to use it
/**
* Audiostack Hello World Example
*
* Add your API key on line 12 and run
* node example.js
*/
// Import the library
const { Audiostack } = require('@aflr/audiostack');
// Provide your api key from the Audiostack Console
const apiKey = 'your_api_key';
/**
* This example demonstrates how to produce and download a file using the Audiostack API.
*/
const example = async () => {
// Create a new instance of Audiostack
const AS = new Audiostack(apiKey);
// Create a script asset with our hello text
const script = await AS.Content.Script.create({
scriptText:
'Hello from Audiostack. This is a test script. I hope you enjoy it.',
});
// Create a speech asset using our script and the voice "sara"
const tts = await AS.Speech.Tts.create({
scriptId: script.scriptId,
voice: 'sara',
});
// Create a mix with our speech asset and add the sound template "3am"
const mix = await AS.Production.Mix.create({
speechId: tts.speechId,
soundTemplate: '3am',
});
// Encode the file to high quality mp3
const encode = await AS.Delivery.Encoder.encodeMix({
productionId: mix.productionId,
preset: 'mp3_high',
});
// Download the file to the project directory
const path = await encode.download();
// Print the path to the file
console.log(`File downloaded to: ${path}`);
};
// Run the example
example();
We look forward to seeing feedback and seeing what YOU build with our SDK.
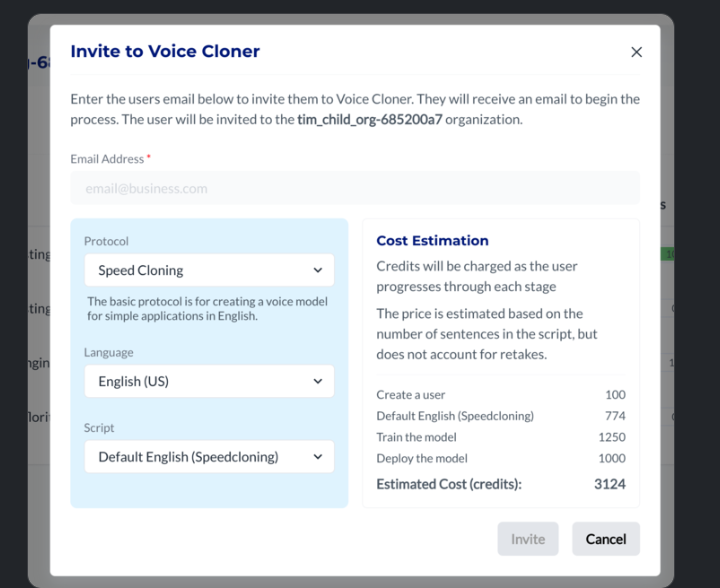
Introduction of Voice Cloning Protocols (Speed, Standard and Premium)
📘
Speed, Standard, Premium
Speed is the basic protocol
The standard protocol contains longer and more thorough scripts which improve the quality of the voice model.
The premium protocol is our best quality voices.
End to End German Voice Pipeline
For 🇩🇪 speaking customers we now have a fully end to end german voice pipeline. So you can record your voice and get a synthetic representation in less than 48 hours. We're continuously working on improving this.
Voice Cloning Billing
We now have enhanced billing for our voice cloning experience.
Dynamic Scripts
We have automatic insertion of First Name, Last Name and Org Name into the script so you can personalise your script to your own use case!
New Console Page
Better UI/UX
Real-time progress monitoring
Here's some screenshots!
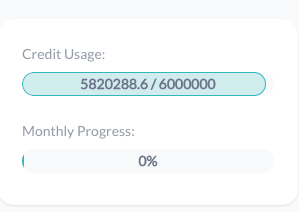
Showing the plan and the number of organisations
Showing your monthly progress and your credit usage
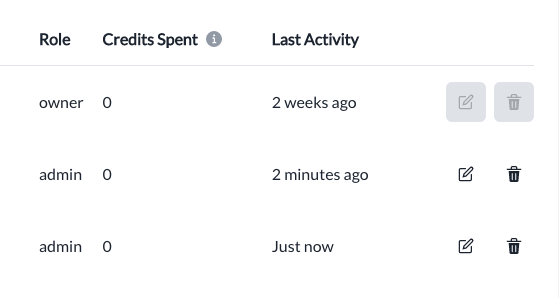
New Account Management Page includes:
Improved UI/UX
Improved Analytics (Last Activity, Number of credits spent by User, Organisation and Account)
Here's a screenshot
Improved Billing Experience
We recently rolled out improvements in our billing experience. This might cause you some differences in your credit costs.
❗️
Changes in billing (costs will change)
You may notice some changes in your billing with these new endpoints.
Provider
Cost in credits per 10 seconds
Messner
1.5
Resemble
9
Deepzen
18
Polly
1
IBM
1
Cerevoice (cereproc)
1.2
Azure
1.2
Google
1
Wellsaid
9
ElevenLabs
12
Bug fixes
We fixed a bug in applying sound effects to messner voices. Now this successfully works.
We want to wish you all a happy easter from all at Aflorithmic!
Here's some things we've launched
ElevenLabs voices are now part of our Library!
ElevenLabs is a voice technology research company, that merely focuses on developing high-quality AI voices for publishers and creators. Their text-to-speech models use high compression and context understanding unparalleled to other artificial voices we have encountered so far.
Currently we have sourced 9 American English voices, both male and female that you can use to render speech ultra-realistically for all your projects! https://library.api.audio/voices?providerFullName=elevenlabs
import audiostack, os
SCRIPT_TEXT = """
<as:section name="intro" soundsegment="intro">
This is the first section and will be combined with the intro music.
</as:section>
<as:section name="main" soundsegment="main">
This is the second section and will be combined with the main music. The section name and soundsegment don't have to have the same name.
</as:section>
"""
audiostack.api_base = "https://v2.api.audio"
audiostack.api_key = os.environ['AUDIOSTACK_API_KEY'] #stick your API key here
VOICE = "wren" #Others include Renata and Bryer
script = audiostack.Content.Script.create(scriptText=SCRIPT_TEXT)
print(script.message, script.scriptId)
tts = audiostack.Speech.TTS.create(scriptItem=script, voice=VOICE, public=True)
print(tts)
SyncTTS
We recently fixed some bugs in SyncTTS and more importantly enabled it for ALL of our voices.
Our profile pictures in the Console sometimes weren't shown, we've updated this so you can see your wonderful user profile picture.
Bug fixes
We fixed a bug that the child organisations weren't inheriting account level voices, so this will mean that if your account is a paid plan the voices (that aren't marked private) will be inherited too. This means a better user experience for your users.
We've been hard at work on improving the reliability and bug fixing based on customer feedback.
Break tag embed - When you used a voice with a style in this format f"""<mstts:express-as style="{style}">{text}</mstts:express-as>"""
and a user embeds <break time="5000ms"/>it wasn't working. We've fixed this break tag embedding issue.
Voice cloning - We've enhanced the voice cloning experience
We've enhanced the reliability and experience of voice cloner, especially in languages such as German 🇩🇪
We also fixed some bugs in the script that was specific to verticals (sales for example) this greatly enhances the experience.
Billing
We've made some improvements to our billing experience, this should reduce errors, and also we've enhanced our operational processes about this.
We've been hard at work on internal stability and performance improvements over the last few weeks. We've seen a significant drop in error rates for most of our customers.
We made significant improvements to our voice intelligence layer and our voice cloning experience.
We'll continue to invest in these improvements.
Voices
We made big improvements to our voice listings, and our styles in our voices.
Excellent work by our solutions team on delivering this, and helping our customers better understand our value prop.
WellSaid’s voices now featuring on our library!
Our latest addition to our 700+ library of synthetic voices are Seattle-based synthetic speech technology startup WellSaid Labs.
They have created a collection of voices with the highest naturalness score. In addition to that, some of their voices support 3 styles: Narration, Promo, and Conversational.
Use the Narration voices if you are after an explanatory, stable and calm delivery of your script, the Promo voices if you are after a more enthusiastic, advert-like style and the Conversational Voices that are optimised for customer interactions. 🎂
Text-to-Speech providers we listed all of our text to speech providers including Well Said labs.
AutoMixingService our audio team has been hard at work on creating an AutoMixingService have a listen and experiment with it with these docs.
Improvements to the sign up experience
We've made a number of improvements to the security and user experience of the sign up experience. We discovered in beta testing that this improved the user onboarding experience.
At Aflorithmic we take really seriously security for customers. So we recently rolled out a new improved user permissions management (which is managed by our customer success team) and have taken user feedback to make this even better.
We've also added enhancements in resource based control. We'll be rolling out more and more features based on this in the coming weeks. However here's a few improvements.
We've a 10x faster system for handling this, and reduced load on our engineering team by 10x, so they can focus on producing features for our customers! 🍮
We've enabled better privacy and control. For example - We are assigning private voices with an owner role of the user, which only has access to certain Operations like invite others and delete the voice.
The premium voice should break because you won't have access to this.
This allows you to have specific voices to specific users. So your PII is better protected.
🔐
We now have a more auditable, better security, and helping protect our customer data, which we take very seriously. 🏁
Bug fixes and enhancements
We fixed a bunch of bugs in the recent release. We can't highlight them all.
However let's celebrate some 💯
We've improved our voice systems - we reduced technical debt and did a whole new design - this will enhance the customer experience and also allow us to ship features faster 🚢
We've made improvements to billing, we've fixed some bugs (for example 2FA didn't work with some credit cards), and enhanced the transparency (it'll be clearer in your reporting). We'll be rolling out further changes in the future. 💰
Our script pipeline was failing silently in some edge cases - now we've fixed this and it fails safely. 👷