Voice Intelligence Layer
The Voice Intelligence Layer is a solution that enhances the naturalness of speech
The Voice Intelligence Layer is AudioStack’s solution that enhances the naturalness of speech. It aims to solve common pronunciation and formatting woes that apply to most users when using a synthetic Voice: quality of speech, pronunciation and contextual recognition.
Voice Intelligence has two main features: Normalizer and LexiThis feature consists of 2 main services to enhance content creation with the most natural and human-like results: Normalizer and Lexi (word dictionaries).
Normalizer
The goal of the Normalizer is that any TTS output to be pronounced consistently across multiple providers, wants acronyms to be read out letter by letter and times as well as dates and numbers to be interpreted correctly (e.g. 1970 -> nineteen seventy, not one thousand nine hundred seventy). Our service applies over 50 linguistic and NLP rules.
Normalizer is German only at the momentDue to its specific challenges, we focused on 🇩🇪 normalization first.
One of the functionalities of the normalizer is to convert Roman numerals into their verbalized forms.
The following example shows the normalization of a Roman numeral used as a cardinal number:
import audiostack
import os
## Add your API Key below
audiostack.api_key = "APIKEY"
text = "Hast du Rocky IV gesehen?"
script = audiostack.Content.Script.create(scriptText=text)
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="lena", voiceIntelligence= True)
print(tts.data['sections'][0]['preview'])This code returns the script as it should be pronounced: Hast du Rocky vier gesehen?
Normalizer exists for all German voices and is activated using a simple flag in the Speech section of your code:voiceIntelligence= True
When Roman numerals are used to identify queens, kings or popes, they are converted into verbalized ordinal numbers:
import audiostack
import os
## Add your API Key below
audiostack.api_key = "APIKEY"
text = "Nach dem Tod Elisabeths II. steht nun die Krönung Charles III an."
script = audiostack.Content.Script.create(scriptText=text)
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="lena", voiceIntelligence= True)
print(tts.data['sections'][0]['preview'])Here, the output would be:
Nach dem Tod Elisabeths der zweiten steht nun die Krönung Charles des dritten an.
Here is an overview of all supported features of Normalizer:
📅 Dates
📅 Disambiguation years/quantifiers
☎️ Telephone numbers
🔢 Ordinal numbers as adverbs
🔢 Ordinal numbers as adjectives
🔢 Decimals
🔣 Other Symbols
🔤 Initialisms
🔤 Acronyms
🔤 Invariable abbreviations
🔤 Variable abbreviations
🕝 Times
➗ Fractions
♾️ Measures, units
💰 Currencies
🕸️ URLs
🆎 Period disambiguation
Lexi (Word Dictionaries)
Lexi, our second layer, can be also thought of as a TTS spell checker for simplicity. Often when working with TTS, the models can fail to accurately pronounce specific words, for example, brands, names and locations. To fix this, we have introduced our lexi flag, which works in a similar way to SSML. This can replace words with either plain text or IPA phonemes. You can selectively replace words based on language, language dialect, provider or exact voice.
For example, adding <!peadar> instead of Peadar to your script will cause the model to produce an alternative pronunciation of this name. This is particularly useful in cases where words can have multiple pronunciations, for example, the cities ‘reading’ and ‘nice’. In this instance placing <!reading> and <!nice> will ensure that these are pronounced correctly, given the script: " The city of <!nice> is a really nice place in the south of France."
If this solution does not work for you, you can instead make use of our custom (self-serve) lexi feature (shown below). This can be used to either correct single words, or expand acronyms. For example, you can replace all occurrences of the word Aflorithmic with “af low rhythmic” or occurrences of the word ‘BMW’ with “Bayerische Motoren Werke''. Replacement words can be supplied as plain text or an IPA phonemicization.
Lexi dictionaries are restricted to organizations in order to avoid spillover of incorrect words or user-specific pronunciations. Just like Normalizer, it's a simple feature flag in the Speech section of your code:voiceIntelligence=True
Dictionaries within Lexi
A dictionary contains a list of words. A single word contains one or more inputs (normally just the word), and one or more replacements. In the vast majority of cases, a single input and single output are contained within a word entry.
There are in total 8 dictionary types, split into two-word types.
universal words = words that have only one pronunciation. i.e. 'because'
homographs = words that have more than one pronunciation, i.e. 'nice' (verb) and 'Nice' (location)
Within these two categories, we maintain the following structure.
For Universal Words
a customer-specific dictionary containing global words (language-agnostic)
a customer-specific dictionary containing language-specific words (i.e. 🇩🇪, 🇬🇧)
an AFLR-specific dictionary containing global words (language-agnostic)
an AFLR-specific dictionary containing language-specific words (i.e. 🇩🇪, 🇬🇧)
For Homograph Words
a customer-specific dictionary containing homographic words (language-agnostic)
a customer-specific dictionary containing language-specific homographic words (i.e. 🇩🇪, 🇬🇧)
an AFLR-specific dictionary containing global homographic words (language-agnostic)
an AFLR-specific dictionary containing language-specific homographic words (i.e. 🇩🇪, 🇬🇧)
A customer only has one global language dictionary, but can have multiple specific language dictionaries, i.e. one for 🇬🇧 and one for 🇩🇪'.
Here is a code example:
# Creates a default entry
entry_default = {
"word" : "sam",
"lang" : "en",
"replacement" : "dr sam",
}
# creates a default entry with IPA
# content type can be either 'basic' (default) or 'ipa'
entry_with_ipa = {
"word" : "sam",
"lang" : "en",
"replacement" : "sæm",
"contentType" : "ipa"
}
# creates a special edge case, i.e. if the user uses voice 'sara' apply this replacement instead
entry_with_specialisation = {
"word" : "sam",
"lang" : "en",
"replacement" : "sææm",
"contentType" : "ipa",
"specialization", "en-us",
"provider" : "azure"
}
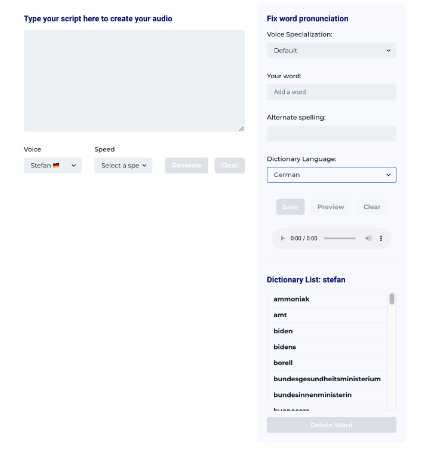
}Front-End Demo Example:
This is what a frontend using Lexi built with AudioStack infrastructure can look like. Given that AudioStack is designed around simple API calls, you can design any frontend around it or integrate it into existing systems.
Please NoteThe Voice Intelligence Layer is also responsible for handling SSML tags. It is therefore automatically set to
Trueif<as: ...>tags are present in the script.
Updated 3 months ago