Annotate Speech with Timestamps
Add timestamps to your speech file to know when specific words are spoken
There are some situations where it's useful to know the exact times when certain words in your speech file are going to be spoken - for example, when dubbing or when matching up speech to video content. Using the /TTS/Annotate endpoint, you can see when each word will be said in your script for a given voice.
Try running the following Python script:
import audiostack
import os
audiostack.api_key = "YOUR_API_KEY"
scriptText = """
<as:section name="intro" soundsegment="intro">
In this example, you can see that it's possible to get a timestamp for every individual word that is produced.
</as:section>
"""
script = audiostack.Content.Script.create(scriptText=scriptText, scriptName="test")
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="joanna")
tts = audiostack.Speech.TTS.annotate(speechId=tts.speechId)This will return an annotated script, complete with timestamps, like so:
[{'Word': 'In', 'Offset': 1100000, 'Duration': 2000000, 'Confidence': 0.98715824}, {'Word': 'this', 'Offset': 3100000, 'Duration': 1600000, 'Confidence': 0.9753032}, {'Word': 'example,', 'Offset': 4700000, 'Duration': 6800000, 'Confidence': 0.9776048}, {'Word': 'you', 'Offset': 12700000, 'Duration': 2000000, 'Confidence': 0.9866327}, {'Word': 'can', 'Offset': 14700000, 'Duration': 1200000, 'Confidence': 0.98713267}, {'Word': 'see', 'Offset': 15900000, 'Duration': 2000000, 'Confidence': 0.9911123}, {'Word': 'that', 'Offset': 17900000, 'Duration': 1600000, 'Confidence': 0.9679997}, {'Word': "it's", 'Offset': 19500000, 'Duration': 2000000, 'Confidence': 0.36796862}, {'Word': 'possible', 'Offset': 21500000, 'Duration': 4800000, 'Confidence': 0.9908886}, {'Word': 'to', 'Offset': 26300000, 'Duration': 800000, 'Confidence': 0.9797738}, {'Word': 'get', 'Offset': 27100000, 'Duration': 1600000, 'Confidence': 0.9913995}, {'Word': 'a', 'Offset': 28700000, 'Duration': 400000, 'Confidence': 0.94052625}, {'Word': 'timestamp', 'Offset': 29100000, 'Duration': 6000000, 'Confidence': 0.41806158}, {'Word': 'for', 'Offset': 35100000, 'Duration': 1600000, 'Confidence': 0.9872579}, {'Word': 'every', 'Offset': 36700000, 'Duration': 4000000, 'Confidence': 0.9776667}, {'Word': 'individual', 'Offset': 40700000, 'Duration': 6000000, 'Confidence': 0.9885981}, {'Word': 'word', 'Offset': 46700000, 'Duration': 2800000, 'Confidence': 0.9805131}, {'Word': 'that', 'Offset': 49500000, 'Duration': 1600000, 'Confidence': 0.9788204}, {'Word': 'is', 'Offset': 51100000, 'Duration': 1200000, 'Confidence': 0.94171035}, {'Word': 'produced.', 'Offset': 52300000, 'Duration': 5700000, 'Confidence': 0.9468268}], 'annotations_seconds': [{'Word': 'In', 'Offset': 0.11, 'Duration': 0.2, 'Confidence': 0.98715824}, {'Word': 'this', 'Offset': 0.31, 'Duration': 0.16, 'Confidence': 0.9753032}, {'Word': 'example,', 'Offset': 0.47, 'Duration': 0.68, 'Confidence': 0.9776048}, {'Word': 'you', 'Offset': 1.27, 'Duration': 0.2, 'Confidence': 0.9866327}, {'Word': 'can', 'Offset': 1.47, 'Duration': 0.12, 'Confidence': 0.98713267}, {'Word': 'see', 'Offset': 1.59, 'Duration': 0.2, 'Confidence': 0.9911123}, {'Word': 'that', 'Offset': 1.79, 'Duration': 0.16, 'Confidence': 0.9679997}, {'Word': "it's", 'Offset': 1.95, 'Duration': 0.2, 'Confidence': 0.36796862}, {'Word': 'possible', 'Offset': 2.15, 'Duration': 0.48, 'Confidence': 0.9908886}, {'Word': 'to', 'Offset': 2.63, 'Duration': 0.08, 'Confidence': 0.9797738}, {'Word': 'get', 'Offset': 2.71, 'Duration': 0.16, 'Confidence': 0.9913995}, {'Word': 'a', 'Offset': 2.87, 'Duration': 0.04, 'Confidence': 0.94052625}, {'Word': 'timestamp', 'Offset': 2.91, 'Duration': 0.6, 'Confidence': 0.41806158}, {'Word': 'for', 'Offset': 3.51, 'Duration': 0.16, 'Confidence': 0.9872579}, {'Word': 'every', 'Offset': 3.67, 'Duration': 0.4, 'Confidence': 0.9776667}, {'Word': 'individual', 'Offset': 4.07, 'Duration': 0.6, 'Confidence': 0.9885981}, {'Word': 'word', 'Offset': 4.67, 'Duration': 0.28, 'Confidence': 0.9805131}, {'Word': 'that', 'Offset': 4.95, 'Duration': 0.16, 'Confidence': 0.9788204}, {'Word': 'is', 'Offset': 5.11, 'Duration': 0.12, 'Confidence': 0.94171035}, {'Word': 'produced.', 'Offset': 5.23, 'Duration': 0.57, 'Confidence': 0.9468268}]It's then possible to format this output however you like.
To format your output data as a table using Python, you can install PandasEnter the command
pip install pandasin your terminal to try this out
Pandas is a useful tool for organising and visualising data in Python. Once you've installed it, you can run the following example to produce an easy to digest table of your script's timestamps.
import audiostack
import os
import pandas as pd
audiostack.api_key = "YOUR_API_KEY"
scriptText = """
<as:section name="intro" soundsegment="intro">
In this example, you can see that it's possible to get a timestamp for every individual word that is produced.
</as:section>
"""
print("Creating your script...")
script = audiostack.Content.Script.create(scriptText=scriptText, scriptName="test")
print("Generating speech...")
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="joanna")
speechId = tts.speechId
print("Downloading your speech file...")
tts.download()
print("Annotating your speech file with time stamps...")
tts = audiostack.Speech.TTS.annotate(speechId=tts.speechId)
print("Formatting your timestamp data as a table...")
data_list = None
for key, value in tts['data'].items():
if 'annotations_timestamps' in value:
data_list = value['annotations_timestamps']
break
df = pd.DataFrame(data_list)
df.rename(columns={'Offset': 'Timestamp'}, inplace=True)
df['Timestamp'] = df['Timestamp'] / 10000000
df['Duration'] = df['Duration'] / 10000000
# Print the formatted table
print(df)As always, don't forget to add your API key in Line 5.
The result should look something like this:
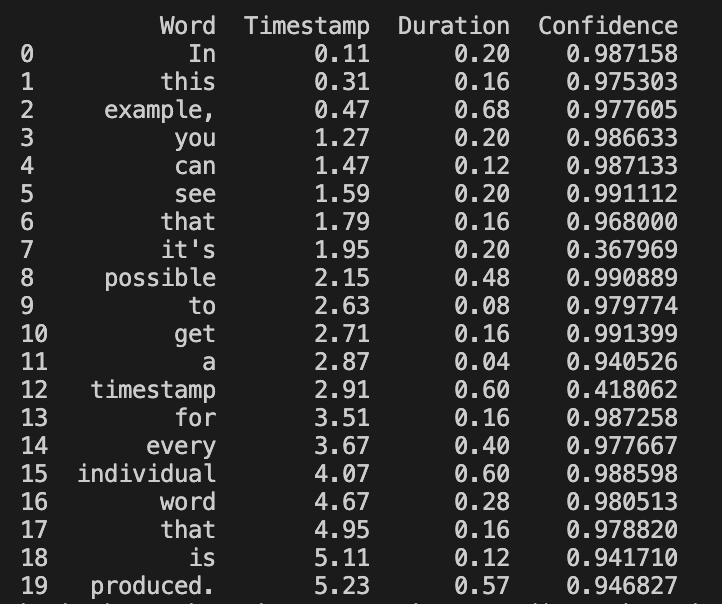
You can now use your timestamps to more accurately coordinate your speech with other content
Want to format this as a transcript and download it as a text file? Check out the code example below:
import audiostack
import os
import pandas as pd
audiostack.api_key = "YOUR_API_KEY"
scriptText = """
<as:section name="intro" soundsegment="intro">
In this example, you can see that it's possible to get a timestamp for every individual word that is produced.
</as:section>
"""
print("Creating your script...")
script = audiostack.Content.Script.create(scriptText=scriptText, scriptName="test")
print("Generating speech...")
tts = audiostack.Speech.TTS.create(scriptItem=script, voice="joanna")
speechId = tts.speechId
print("Downloading your speech file...")
tts.download()
print("Annotating your speech file with time stamps...")
tts = audiostack.Speech.TTS.annotate(speechId=tts.speechId)
print("Formatting your timestamp data as a table...")
data_list = None
for key, value in tts['data'].items():
if 'annotations_timestamps' in value:
data_list = value['annotations_timestamps']
break
df = pd.DataFrame(data_list)
df.rename(columns={'Offset': 'Timestamp'}, inplace=True)
df['Timestamp'] = df['Timestamp'] / 10000000
df['Duration'] = df['Duration'] / 10000000
# Print the formatted table
print(df)
print("Generating a transcript...")
# Function to format the transcript for a given row
def format_transcript(row):
start_time = row['Timestamp'].iloc[0]
end_time = row['Timestamp'].iloc[-1] + row['Duration'].iloc[-1]
words = ' '.join(row['Word'])
return f"{start_time:.2f}-{end_time:.2f}\n\"{words}\""
# Group the data by continuous Timestamps and apply the format_transcript function
formatted_transcript = df.groupby((df['Timestamp'] != df['Timestamp'].shift(1) - df['Duration'].shift(1)).cumsum()).apply(format_transcript)
# Print the formatted transcript
print("Your Timestamped Transcript:")
# Initialize variables
segments = []
current_segment = pd.DataFrame(columns=['Word', 'Timestamp', 'Duration', 'Confidence'])
# Iterate through the data and create segments with at least 5 words
for _, row in df.iterrows():
current_segment = pd.concat([current_segment, row.to_frame().T], ignore_index=True)
words_in_segment = ' '.join(current_segment['Word']).split()
if len(words_in_segment) >= 5: # This means that there are 5 words between each timestamp marker
segments.append(current_segment)
current_segment = pd.DataFrame(columns=['Word', 'Timestamp', 'Duration', 'Confidence'])
# If there are remaining words in the current segment, add it to the segments
if not current_segment.empty:
segments.append(current_segment)
# Delete any existing content in the transcript file
f = open("transcript.txt", "w")
f.close()
# Format and print the segments
for segment in segments:
formatted_segment = format_transcript(segment)
print(formatted_segment)
f = open("transcript.txt", "a")
print(f"{formatted_segment}", file=f)
f.close()This script will generate a text file that you can share or upload as needed.

The finished transcript 🚀
Updated 3 months ago
Check out our other features for creating video voiceovers, or generate a .SRT file for YouTube: