Denoise your noisy audio files
- Added an improved denoiser - you can check it out here Denoise an audio file.
Docs improvements
We added some improvements to improve the onboarding experience 💯
-
https://docs.audiostack.ai/docs/how-do-we-do-turn-a-csv-file-into-audio
-
https://docs.audiostack.ai/docs/how-to-make-beautiful-audio-in-seconds
Improvements
- We added zip downloader added to the api for exporting zips ⚡
Platform
- Users can join a Waitlist for the ‘Coming Soon’ Workflows
- Implement security headers into nextjs apps enhancing our security 🔒
- Users can now brand the Platform with their logo - a much requested feature
- Audio title encoding in the links to player doesn’t support special chars 🐛
- The voice library now shows the best voices at the top
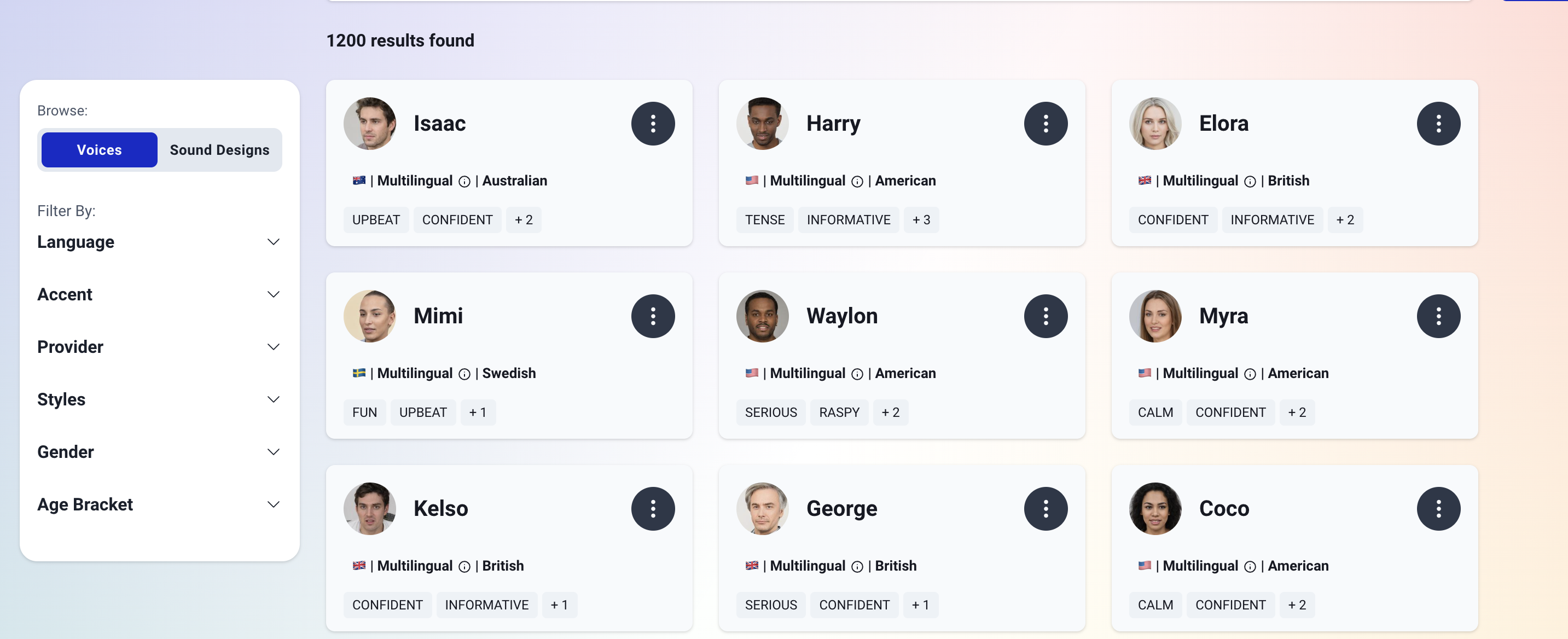
Check out the libraryYou can check it out at our Library page!
SonicSell
- AdCards now provide better error feedback for invalid input
-
SDK
- Bug fixes in the voice cloning experience 🐛