Voice Cloner
Find out more about how to clone voices using AudioStack
There are two main routes to cloning your voice with AudioStack: you can either upload an existing recording to your files and generate a clone from there, or record your voice directly into the Recording Booth.
First Route: Clone your Voice from a File Upload
Step One
Upload an audio file to your Content area, or select one that's been uploaded by a colleague.
Be sure you have permission to clone the voice you're usingMake sure you review our Terms of Use and Privacy Policy.
Step Two
Once the file is uploaded, click on it to preview that the file is correct, and give it the category "voice".
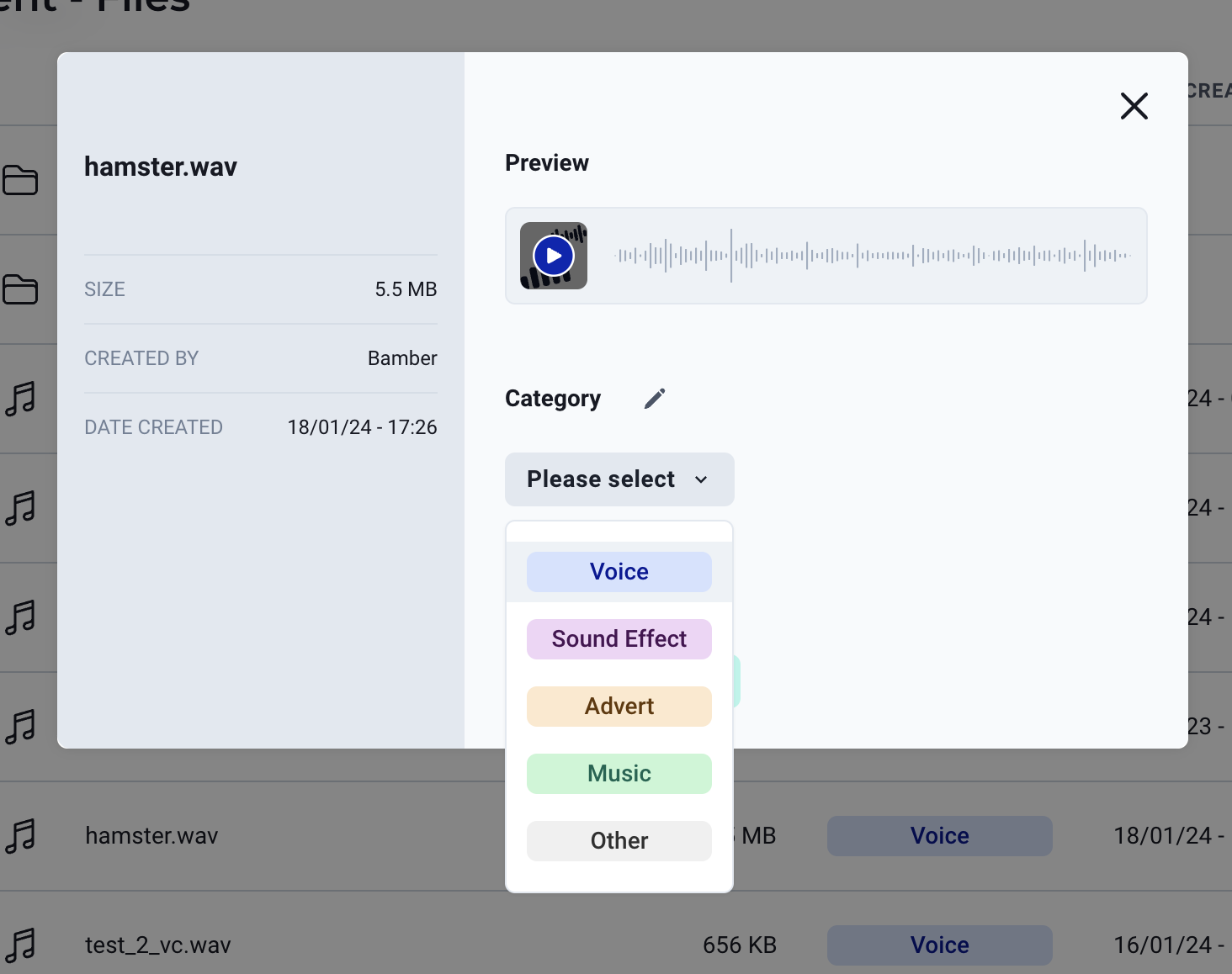
Step Three
In the Files area, you'll now be able to see the cloning icon ✨
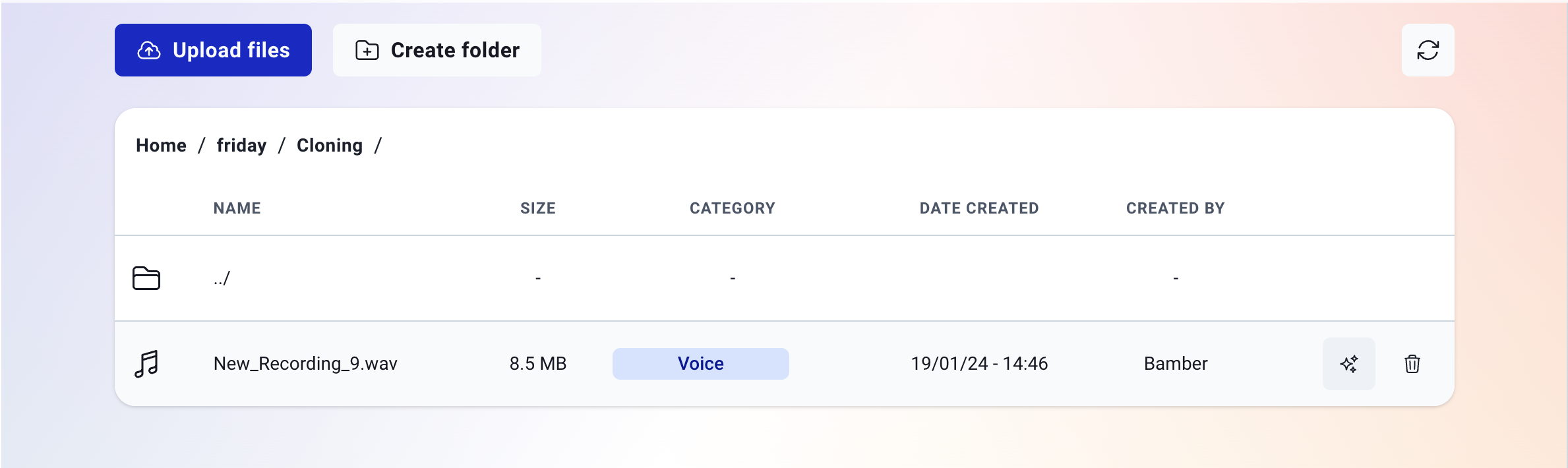
Click on this icon, review and accept the terms of use and privacy policy, and your voice will be cloned right away!
Within minutes, your clone will be available to try out in the Voice Library. Cloned voices are usable throughout all of our workflows by the voice owner and your organisation's administrators.
Enjoy using your cloned voice!Try using your voice in a workflow such as SonicSell or Speech Playground
Second Route: Clone your Voice from Recording Booth
Step One
Go to the Resources / Speech page and click "Clone your Voice"
Step Two
You'll be taken to the Recording Booth, where you can capture a recording. If you need more information about how to capture a recording, follow our guide here.
Note that all files recorded or uploaded can be viewed by anyone in your organisationIf you want to restrict access to certain users for sensitive content, you can create a "child" organisation to restrict the access to certain users in your team.
Step Three
Save your recording by clicking on the Save button next to the preview at the bottom of the page.

You'll then see an option to evaluate your audio quality, clone your voice, or view the result in your files.
Step Four
🌈 Your cloned voice should now be available to use!
🎤 Best Practices for Cloning your Voice 🎤
In order to ensure quality and make sure your time is being used correctly, we recommend the following for your recording environment and equipment. Input means output in voice cloning-the clearer and closer to the desired speaking style your recordings are, the more lifelike your synthetic voice will turn out.
✅Understanding the Nuances:
Before delving into the intricacies of voice cloning, it's crucial to comprehend the underlying principles. Voice cloning is exceptionally accurate in replicating the samples it's trained on, capturing both the nuances and imperfections of the provided audio. This includes background noise, room reverb, or any other unintended sounds present in the training samples.
✅Maintaining Clarity:
A fundamental aspect to ensure optimal results is maintaining clarity in the training data. The AI thrives when presented with a single, consistent speaking voice throughout the recordings. The introduction of multiple speakers or excessive noise can lead to confusion, hindering the AI's ability to discern the intended voice accurately.
✅Crafting the Desired Style:
The speaking style embedded in the training samples directly influences the output. Whether you aim to replicate your voice for an audiobook or any other purpose, align the training data with the desired style. Consistency in style within the uploaded samples is paramount for achieving the desired results.Think about what your voice will be used for, and make sure you consistently use that tone of voice, speaking style and energy.
🎤Best Practices for Recording Your Voice: 🎤
-
Professional Recording Equipment:
We highly recommend that you do not use any type of lavalier, boom, laptop, desktop or mobile phone microphones. What we do recommend is anything in the range of Yeti Blue USB Microphone, Shure SM57 (w/ Focusrite 2i2 Interface), Rode NT-USB Microphone. For best results, we recommend you use a MacBook and Google Chrome. -
Microphone Distance:
Position yourself at the recommended distance, approximately two fists away from the microphone, adjusting based on the recording type. -
Pop-Filter Usage:
Minimize plosives during recording by using a pop-filter if available, or try to soften your delivery. -
Noise-Free Recording:
Ensure a clean audio input by eliminating interference such as background music or noise. -
Room Acoustics:
Record in an acoustically-treated room to reduce echoes and background noises. If this is not possible or you have a home setup, choose the quietest space in your house that does not have echoes. Turn off all air conditioning, fans and make sure there are no other people in the room while recording. -
Recording quality:
Recording quality 44.1 kHz 16-bit or better. 48 kHz 24-bit is common and desirable -
Sufficient Audio Length:
For instant cloning, you can get reasonable quality results with shorter amounts of audio than ever before. Even so, we recommend using a recording that's at least 5 minutes in length for a reasonable quality instant clone - ideally longer if possible. The instant cloner will support recording durations up to over 35 minutes. -
Speaking Style:
The quality of your voice model heavily depends on the quality of the recorded voice that is used for training. The volume, speaking rate, pitch, and expressive mannerisms must all remain consistent throughout the recording process. If you choose to do the recording over multiple sessions, it’s important that they sound like they were done on the same day in the same room. To avoid inconsistency we recommend doing it in one session, or as few as possible.
✳️ Make sure you have access to some drinking water. It will help keep your voice nice and clear.
✳️ You should not add distinct pauses between words except if there are punctuation marks.
✳️ Think about what your voice will be used for, and make sure you consistently use that tone of voice, speaking style and energy. -
📜 Script Expectations:scroll:
In the script that you read, there might be some acronyms such as F B I, NASA etc. Please read these as they appear in the sentence. For example, if there is a space or full stop between the letters, then you will need to read it letter by letter such as F B I, and if there aren’t any spaces, then you can read the whole word itself, such as NASA.
The spoken words must match the text exactly. Every word of the script should be pronounced as it is written. Sounds should not be omitted or slurred together, as is common in casual speech, unless they have been written that way in the script. Especially things like “I am”, should not be spoken as “I’m” , or “you will” as “you’ll” and so on.
🎩 In conclusion, the success of voice cloning depends on the meticulous application of these best practices. For those eager to embark on the journey of creating lifelike voice clones, adherence to these guidelines ensures predictability and an authentic outcome. For further assistance and inquiries, do not hesitate to reach out to [email protected].
🌈Embark on the exciting journey of voice cloning with confidence, armed with the knowledge to create stunningly authentic reproductions of your voice!
Updated about 2 months ago