Generate Speech Files using Speech-to-Speech (STS)
Bring your Synthetic Speech to Life with STS
With STS, you can apply all of the characteristics of a voice recording onto one of the synthetic voices available in our Voice Library, allowing you to more precisely control the emotional expression, tone, timing and pronunciation of your generated speech.
STS is currently only available on a limited number of voices, but you can now generate it directly in the AudioStack platform, no coding needed. Simply upload a voice recording of the speech you'd like the synthetic voice to replicate in the Files page.
The maximum file size for STS is currently 50mbUploaded files must be smaller than 50mb for STS to be generated.
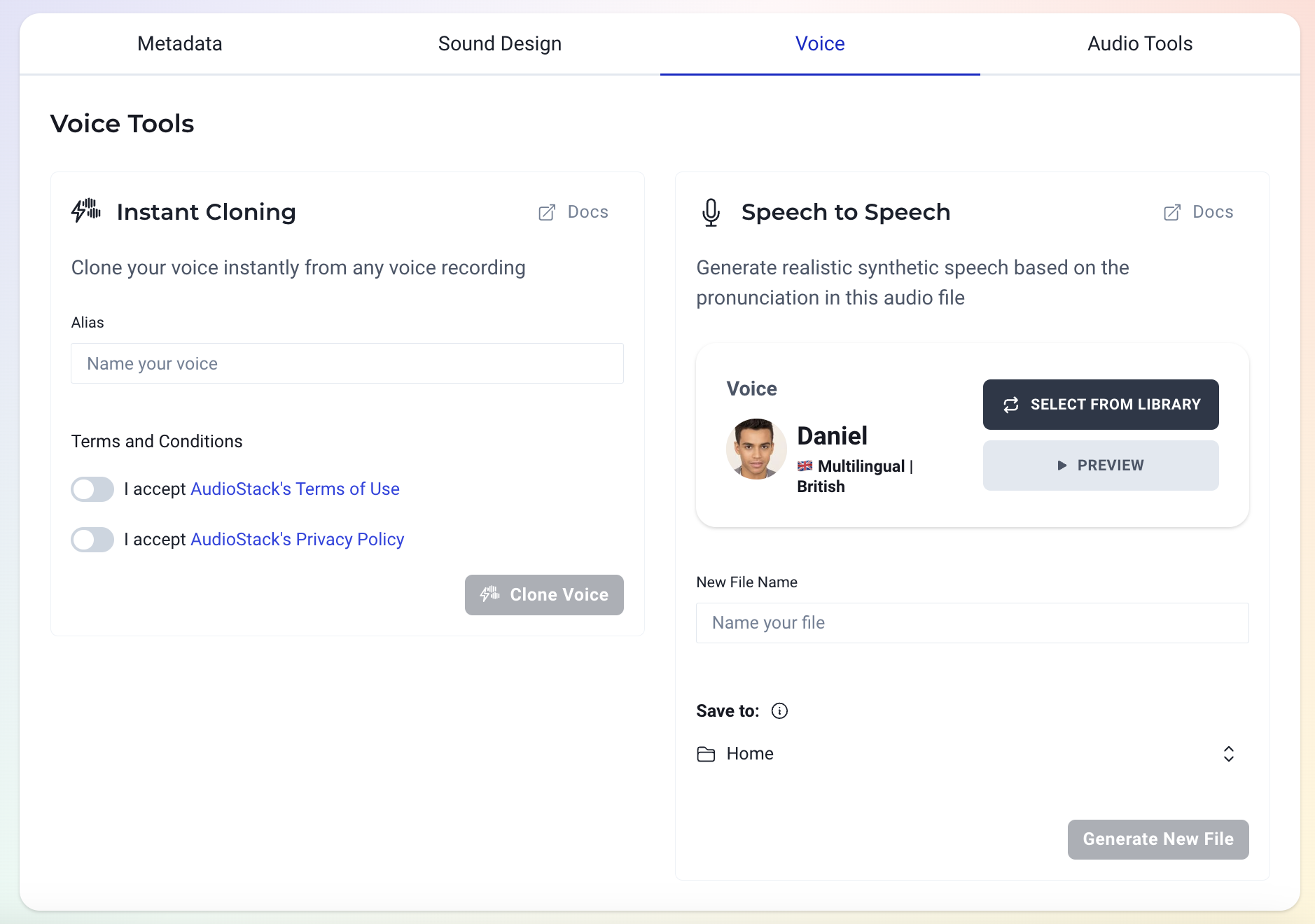
Next, open up the speech file and in the metadata, set the file type to Voice. Then, you'll be able to access the Voice tab.
In the Voice tab, select the voice you'd like to have perform from our extensive library of STS voices, and click Generate. It's as easy as that. Your speech will be generated as an audio file, which can either be downloaded to use in another piece of software, or used within another workflow or in the AudioStack API.
How can I use my STS output using the API?
When working with AudioStack API, you can use Speech-to-Speech in extremely flexible ways.
Check out our tutorial on how to overlay media content with generated audio here.
Why can't I use the whole voice library with STS?
Over time, more voices will become enabled to use STS. At the moment, only a limited number of voice providers support this.
How can I see which voices support STS?
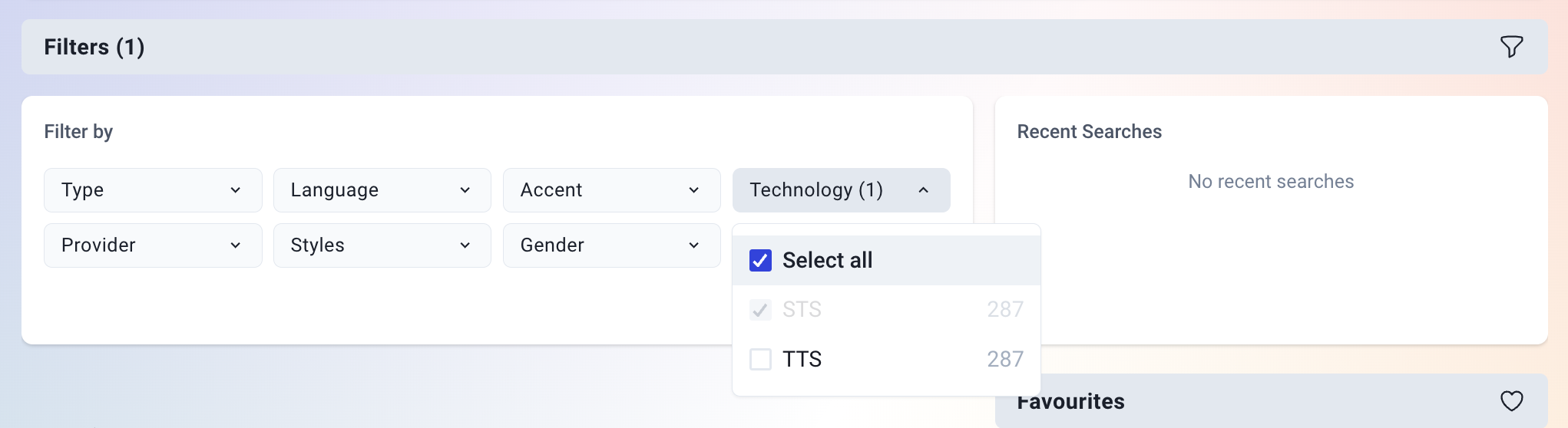
To see which voices are available for Speech-to-Speech, go to the Voice Library (this can be accessed from the Voice tab in Files, so you don't need to leave the page). Click on the Technology filter and select STS. This filter will automatically be applied if you're opening the Voice Library from the Voice tab in Files.
Can I use my generated STS in my advert, in the platform?
Currently, the way to do this is by using an SSML tag in your script, which tells the system which media file you would like to play, and when. Your script in Workshop would look like this:
This is my script, read in TTS. <as:media id="ID" name="NAME" /> You can end with more TTS
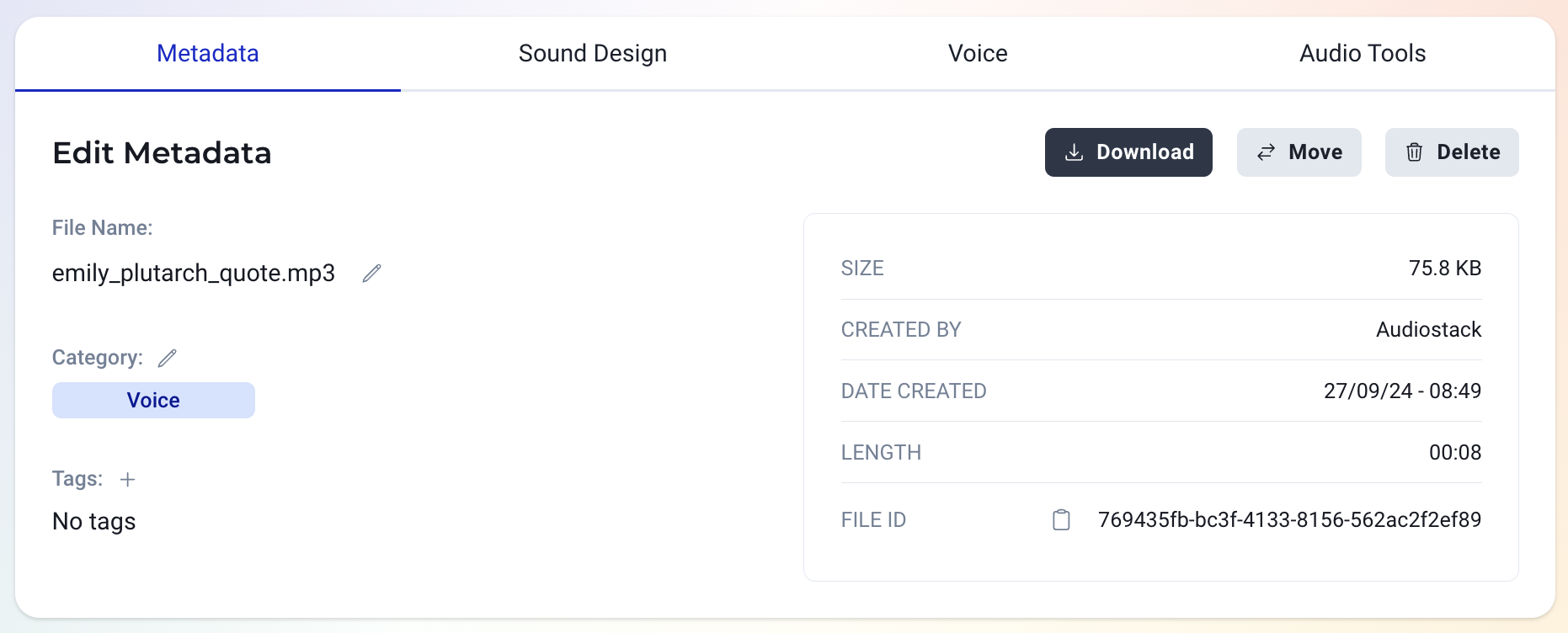
Here, you would need the ID for the media file, which can be found in Files (example below) and the file's name.
We are working on simpler ways to use STS in your generated audio assets - watch this space 👀.
Updated 3 months ago